


IX. Les tripes de Git▲
Vous êtes peut-être arrivé à ce chapitre en en sautant certains ou après avoir parcouru tout le reste du livre. Dans tous les cas, c'est ici que l'on parle du fonctionnement interne et de la mise en œuvre de Git. Pour moi, leur apprentissage a été fondamental pour comprendre à quel point Git est utile et puissant, mais d'autres soutiennent que cela peut être source de confusion et être trop complexe pour les débutants. J'en ai donc fait le dernier chapitre de ce livre pour que vous puissiez le lire tôt ou tard lors de votre apprentissage. Je vous laisse le choix.
Maintenant que vous êtes ici, commençons. Tout d'abord et même si ce n'est pas clair tout de suite, Git est fondamentalement un système de fichiers adressables par contenu (content-addressable filesystem) avec l'interface utilisateur d'un VCS au-dessus. Vous en apprendrez plus à ce sujet dans quelques instants.
Aux premiers jours de Git (surtout avant la version 1.5), l'interface utilisateur était beaucoup plus complexe, car elle était centrée sur le système de fichier plutôt que sur l'aspect VCS. Ces dernières années, l'interface utilisateur a été peaufinée jusqu'à devenir aussi cohérente et facile à utiliser que n'importe quel autre système. Pour beaucoup, l'image du Git des débuts avec son interface utilisateur complexe et difficile à apprendre est toujours présente. La couche système de fichiers adressables par contenu est vraiment géniale et j'en parlerai dans ce chapitre. Ensuite, vous apprendrez les mécanismes de transport/transmission/communication ainsi que les tâches que vous serez amené à accomplir pour maintenir un dépôt.
IX-A. Plomberie et porcelaine▲
Ce livre couvre l'utilisation de Git avec une trentaine de verbes comme checkout, branch, remote … Mais, puisque Git était initialement une boîte à outils (N.d.T : Toolkit) pour VCS, plutôt qu'un VCS complet et convivial, il dispose de tout un ensemble d'actions pour les tâches bas niveau qui étaient conçues pour être liées à la UNIX ou appelées depuis des scripts. Ces commandes sont dites commandes de “plomberie? (N.d.T “plumbing?) et les autres, plus conviviales sont appelées “porcelaines? (N.d.T : “porcelain?).
Les huit premiers chapitres du livre concernent presque exclusivement les commandes porcelaine. Par contre, dans ce chapitre, vous serez principalement confronté aux commandes de plomberie bas niveaux, car elles vous donnent accès au fonctionnement interne de Git et aident à montrer comment et pourquoi Git fonctionne comme il le fait. Ces commandes ne sont pas faites pour être utilisées à la main sur ligne de commandes, mais sont plutôt utilisées comme briques de base pour écrire de nouveaux outils et scripts personnalisés.
Quand vous exécutez git init dans un nouveau répertoire ou un répertoire existant, Git crée un répertoire .git qui contient presque tout ce que Git stocke et manipule. Si vous voulez sauvegarder ou cloner votre dépôt, copier ce seul répertoire suffirait presque. Ce chapitre traite principalement de ce que contient ce répertoire. Voici à quoi il ressemble :
$ ls
HEAD
branches/
config
description
hooks/
index
info/
objects/
refs/Vous y verrez sans doute d'autres fichiers, mais ceci est un dépôt qui vient d'être crée avec git init et c'est ce que vous verrez par défaut. Le répertoire branches n'est pas utilisé par les versions récentes de Git et le fichier description est utilisé uniquement par le programme GitWeb, il ne faut donc pas s'en soucier. Le fichier config contient les options de configuration spécifiques à votre projet et le répertoire info contient un fichier listant les motifs que vous souhaitez ignorer et que vous ne voulez pas mettre dans un fichier .gitignore. Le répertoire hooks contient les scripts de procédures automatiques côté client ou serveur, ils sont décrits en détail dans le chapitre 6.
Il reste quatre éléments importants : les fichiers HEAD et index, ainsi que les répertoires objects et refs. Ce sont les composants principaux d'un dépôt Git. Le répertoire objects stocke le contenu de votre base de données, le répertoire refs stocke les pointeurs vers les objets commit de ces données (branches), le fichier HEAD pointe sur la branche qui est en cours dans votre répertoire de travail (checkout) et le fichier index est l'endroit où Git stocke les informations sur la zone d'attente. Vous allez maintenant plonger en détail dans chacune de ces sections et voir comment Git fonctionne.
IX-B. Les objets Git▲
Git est un système de fichiers adressables par contenu. Super ! Mais qu'est-ce que ça veut dire? Ça veut dire que le cœur de Git est une simple base de paires clef/valeur. Vous pouvez y insérer n'importe quelle sorte de données et il vous retournera une clé que vous pourrez utiliser à n'importe quel moment pour récupérer ces données. Pour illustrer cela, vous pouvez utiliser la commande de plomberie hash-object, qui prend des données, les stocke dans votre répertoire .git, puis retourne la clé sous laquelle les données sont stockées. Tout d'abord, créez un nouveau dépôt Git et vérifiez que rien ne se trouve dans le répertoire object :
$ mkdir test
$ cd test
$ git init
Initialized empty Git repository in /tmp/test/.git/
$ find .git/objects
.git/objects
.git/objects/info
.git/objects/pack
$ find .git/objects -type f
$Git a initialisé le répertoire objects et y a créé les sous-répertoires pack et info, mais ils ne contiennent pas de fichier régulier. Maintenant, stockez du texte dans votre base de données Git :
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4L'option -w spécifie à hash-object de stocker l'objet, sinon la commande répondrait seulement quelle serait la clé. --stdin spécifie à la commande de lire le contenu depuis l'entrée standard, sinon hash-object s'attend à trouver un chemin vers un fichier. La sortie de la commande est une empreinte de 40 caractères. C'est l'empreinte SHA-1 : une somme de contrôle du contenu du fichier que vous stockez plus un en-tête, dont les détails sont un peu plus bas. Voyez maintenant comment Git a stocké vos données :
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4Vous pouvez voir un fichier dans le répertoire objects. C'est comme cela que Git stocke initialement du contenu : un fichier par contenu, nommé d'après la somme de contrôle SHA-1 du contenu et de son en-tête. Le sous-répertoire est nommé d'après les 2 premiers caractères de l'empreinte et le fichier d'après les 38 caractères restants.
Vous pouvez récupérer le contenu avec la commande cat-file. Cette commande est un peu le couteau suisse pour l'inspection des objets Git. Utiliser l'option -p avec cat-file vous permet de connaître le type de contenu et de l'afficher clairement :
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test contentVous pouvez maintenant ajouter du contenu à Git et le récupérer. Vous pouvez aussi faire ceci avec des fichiers. Par exemple, vous pouvez mettre en œuvre une gestion de version simple d'un fichier. D'abord, créez un nouveau fichier et enregistrez son contenu dans la base de données :
$ echo 'version 1' > test.txt
$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30Puis, modifiez le contenu du fichier et enregistrez-le à nouveau :
$ echo 'version 2' > test.txt
$ git hash-object -w test.txt
1f7a7a472abf3dd9643fd615f6da379c4acb3e3aVotre base de données contient les 2 versions du fichier, ainsi que le premier contenu que vous avez stocké ici :
$ find .git/objects -type f
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4Vous pouvez restaurer le fichier à sa première version :
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
$ cat test.txt
version 1ou à sa seconde version :
$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt
$ cat test.txt
version 2Se souvenir de la clé SHA-1 de chaque version de votre fichier n'est pas pratique. En plus, vous ne stockez pas le fichier lui-même, mais seulement son contenu, dans votre base. Ce type d'objet est appelé un blob (Binary Large OBject, soit en français : Gros Objet Binaire). Git peut vous donner le type d'objet de n'importe quel objet Git, étant donné sa clé SHA-1, avec cat-file -t :
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
blobIX-B-1. Objets arbre▲
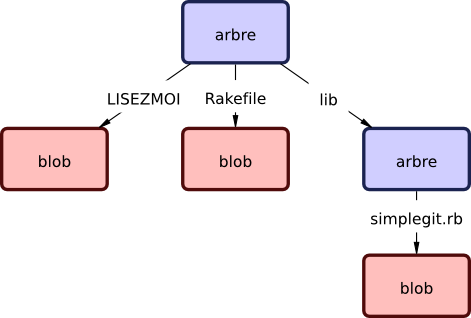
Le prochain type que vous allez étudier est l'objet arbre (N.d.t ‘tree') qui résout le problème de stockage d'un groupe de fichiers. Git stocke du contenu de la même manière, mais plus simplement, qu'un système de fichier UNIX. Tout le contenu est stocké comme des objets de type arbre ou blob : un arbre correspondant à un répertoire UNIX et un blob correspond à peu près à un i-nœud ou au contenu d'un fichier. Un unique arbre contient une ou plusieurs entrées de type arbre, chacune incluant un pointeur SHA-1 vers un blob, un sous-arbre (N.d.T sub-tree), ainsi que les droits d'accès (N.d.t ‘mode'), le type et le nom de fichier. L'arbre le plus récent du projet simplegit pourrait ressembler, par exemple à ceci :
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 libLa syntaxe master^{tree} signifie l'objet arbre qui est pointé par le dernier commit de la branche master. Remarquez que le sous-répertoire lib n'est pas un blob, mais un pointeur vers un autre arbre :
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rbConceptuellement, les données que Git stocke ressemblent à la Figure 9-1.
Vous pouvez créer votre propre arbre. Git crée habituellement un arbre à partir de l'état de la zone d'attente ou de l'index. Pour créer un objet arbre, vous devez donc d'abord mettre en place un index en mettant quelques fichiers en attente. Pour créer un index contenant une entrée, la première version de votre fichier text.txt par exemple, utilisons la commande de plomberie update-index. Vous pouvez utiliser cette commande pour ajouter artificiellement une version plus ancienne à une nouvelle zone d'attente. Vous devez utiliser les options --add car le fichier n'existe pas encore dans votre zone d'attente (vous n'avez même pas encore mis en place une zone d'attente) et --cacheinfo car le fichier que vous ajoutez n'est pas dans votre répertoire, mais dans la base de données. Vous pouvez ensuite préciser le mode, SHA-1 et le nom de fichier :
$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txtDans ce cas, vous précisez le mode 100644, qui signifie que c'est un fichier normal. Les alternatives sont 100755, qui signifie que c'est un exécutable et 120000, qui précise que c'est un lien symbolique. Le concept de « mode » a été repris des mode UNIX, mais est beaucoup moins flexible : ces trois modes sont les seuls valides pour Git, pour les fichiers (blobs) (bien que d'autres modes soient utilisés pour les répertoires et sous-modules).
Vous pouvez maintenant utiliser la commande write-tree pour écrire la zone d'attente dans un objet arbre. L'option' -w est inutile (appeler write-tree crée automatiquement un objet arbre à partir de l'état de l'index si cet arbre n'existe pas) :
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txtVous pouvez également vérifier que c'est un objet arbre :
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
treeVous allez créer maintenant un nouvel arbre avec la seconde version de test.txt et un nouveau fichier :
$ echo 'new file' > new.txt
$ git update-index test.txt
$ git update-index --add new.txtVotre zone d'attente contient maintenant la nouvelle version de test.txt ainsi qu'un nouveau fichier new.txt. Enregistrez cet arbre (c'est-à-dire. enregistrez l'état de la zone d'attente ou de l'index dans un objet arbre) :
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
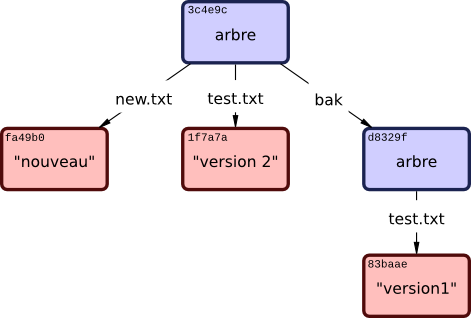
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txtRemarquez que cet arbre contient des entrées pour les deux fichiers et que l'empreinte SHA de test.txt est l'empreinte de la « version 2 » de tout à l'heure (1f7a7a). Pour le plaisir, ajoutez le premier arbre à celui-ci, en tant que sous-répertoire. Vous pouvez maintenant récupérer un arbre de votre zone d'attente en exécutant read-tree. Dans ce cas, vous pouvez récupérer un arbre existant dans votre zone d'attente comme étant un sous-arbre en utilisant l'option --prefix de read-tree :
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txtSi vous créez un répertoire de travail à partir du nouvel arbre que vous venez d'enregistrer, vous aurez deux fichiers à la racine du répertoire de travail, ainsi qu'un sous-répertoire appelé bak qui contient la première version du fichier test.txt. Vous pouvez vous représenter les données que Git utilise pour ces structures comme sur la Figure 9-2.
IX-B-2. Objets Commit▲
Vous avez trois arbres qui définissent différents instantanés du projet que vous suivez, mais certains problèmes persistent : vous devez vous souvenir des valeurs des trois empreintes SHA-1 pour accéder aux instantanés. Vous n'avez pas non plus d'information sur qui a enregistré les instantanés, quand et pourquoi. Ce sont les informations élémentaires qu'un objet commit stocke pour vous.
Pour créer un objet commit, il suffit d'exécuter commit-tree, de préciser l'empreinte SHA-1 et quel objet commit, s'il y en a, le précède directement. Commencez avec le premier arbre que vous avez créé :
$ echo 'first commit' | git commit-tree d8329f
fdf4fc3344e67ab068f836878b6c4951e3b15f3dVous pouvez voir votre nouvel objet commit avec cat-file :
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <schacon@gmail.com> 1243040974 -0700
committer Scott Chacon <schacon@gmail.com> 1243040974 -0700
first commitLe format d'un commit est simple : il contient l'arbre racine de l'instantané du projet à ce moment, les informations sur l'auteur et le validateur qui sont extraites des variables de configuration user.name et user.email accompagnées d'un horodatage, une ligne vide et le message de validation.
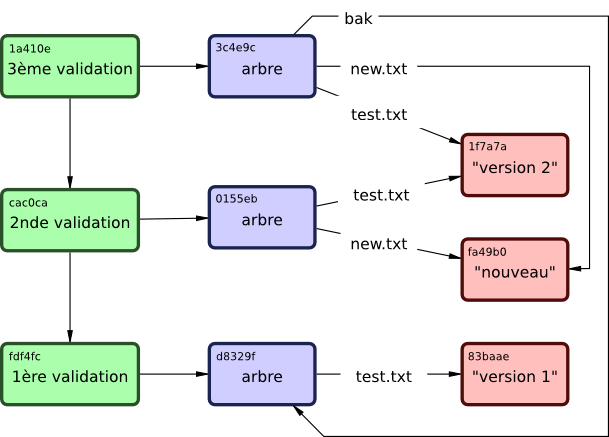
Ensuite, vous enregistrez les deux autres objets commit, chacun référençant le commit dont il est issu :
$ echo 'second commit' | git commit-tree 0155eb -p fdf4fc3
cac0cab538b970a37ea1e769cbbde608743bc96d
$ echo 'third commit' | git commit-tree 3c4e9c -p cac0cab
1a410efbd13591db07496601ebc7a059dd55cfe9Chacun des trois objets commit pointe sur un arbre de l'instantané que vous avez créé. Curieusement, vous disposez maintenant d'un historique Git complet que vous pouvez visualiser avec la commande git log, si vous la lancez sur le SHA-1 du dernier commit :
$ git log --stat 1a410e
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
third commit
bak/test.txt | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:14:29 2009 -0700
second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletions(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:09:34 2009 -0700
first commit
test.txt | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)Fantastique. Vous venez d'effectuer les opérations bas niveaux pour construire un historique Git sans avoir utilisé aucune des commandes haut niveau. C'est l'essence de ce que fait Git quand vous exécutez les commandes git add et git commit. Il stocke les blobs correspondant aux fichiers modifiés, met à jour l'index, écrit les arbres et ajoute les objets commit qui référencent les arbres racines venant juste avant eux. Ces trois objets principaux (le blob, l'arbre et le commit) sont initialement stockés dans des fichiers séparés du répertoire .git/objects. Voici tous les objets contenus dans le répertoire exemple, commentés d'après leur contenu :
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1Si vous suivez les pointeurs internes de ces objets, vous obtenez un graphe comme celui de la Figure 9-3.
IX-B-3. Stockage des objets▲
On a parlé plus tôt de l'en-tête présent avec le contenu. Prenons un moment pour étudier la façon dont Git stocke les objets. On verra comment stocker interactivement un objet Blob (ici, la chaîne “what is up, doc??) avec le langage Ruby. Vous pouvez démarrer Ruby en mode interactif avec la commande irb :
$ irb
>> content = "what is up, doc?"
=> "what is up, doc?"Git construit un en-tête qui commence avec le type de l'objet, ici un blob. Ensuite, il ajoute un espace suivi de taille du contenu et enfin un octet nul :
>> header = "blob #{content.length}\0"
=> "blob 16\000"Git concatène l'en-tête avec le contenu original et calcule l'empreinte SHA-1 du nouveau contenu. En Ruby, vous pouvez calculer l'empreinte SHA-1 d'une chaîne, en incluant la bibliothèque « digest/SHA-1 » via la commande require, puis en appelant Digest::SHA1.hexdigest() sur la chaîne :
>> store = header + content
=> "blob 16\000what is up, doc?"
>> require 'digest/sha1'
=> true
>> sha1 = Digest::SHA1.hexdigest(store)
=> "bd9dbf5aae1a3862dd1526723246b20206e5fc37"Git compresse le nouveau contenu avec zlib, ce que vous pouvez faire avec la bibliothèque zlib de Ruby. Vous devez inclure la bibliothèque et exécuter Zlib::Deflate.deflate() sur le contenu :
>> require 'zlib'
=> true
>> zlib_content = Zlib::Deflate.deflate(store)
=> "x\234K\312\311OR04c(\317H,Q\310,V(-\320QH\311O\266\a\000_\034\a\235"Finalement, vous enregistrerez le contenu compressé dans un objet sur le disque. Vous déterminerez le chemin de l'objet que vous voulez enregistrer (les deux premiers caractères de l'empreinte SHA-1 formeront le nom du sous-répertoire et les 38 derniers formeront le nom du fichier dans ce répertoire). En Ruby, on peut utiliser la fonction FileUtils.mkdir_p() pour créer un sous-répertoire s'il n'existe pas. Ensuite, ouvrez le fichier avec File.open() et enregistrez le contenu compressé en appelant la fonction write() sur la référence du fichier :
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
=> ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
>> require 'fileutils'
=> true
>> FileUtils.mkdir_p(File.dirname(path))
=> ".git/objects/bd"
>> File.open(path, 'w') { |f| f.write zlib_content }
=> 32C'est tout ! Vous venez juste de créer un objet Blob valide. Tous les objets Git sont stockés de la même façon, mais avec des types différents : l'en-tête commencera par « commit » ou « tree » au lieu de la chaîne « blob ». Bien que le contenu d'un blob puisse être presque n'importe quoi, le contenu d'un commit ou d'un arbre est formaté d'une façon particulière.
IX-C. Références Git▲
On peut exécuter quelque chose comme git log 1a410e pour visualiser tout l'historique, mais il faut se souvenir que 1a410e est le dernier commit afin de parcourir l'historique et trouver tous ces objets. Vous avez besoin d'un fichier ayant un nom simple qui contient l'empreinte SHA-1 afin d'utiliser ce pointeur plutôt que l'empreinte SHA-1 elle-même.
Git appelle ces pointeurs des « références », ou « refs ». On trouve les fichiers contenant des empreintes SHA-1 dans le répertoire git/refs. Dans le projet actuel, ce répertoire ne contient aucun fichier, mais possède une structure simple :
$ find .git/refs
.git/refs
.git/refs/heads
.git/refs/tags
$ find .git/refs -type f
$Pour créer une nouvelle référence servant à ce souvenir du dernier commit, vous pouvez simplement faire ceci :
$ echo "1a410efbd13591db07496601ebc7a059dd55cfe9" > .git/refs/heads/masterVous pouvez maintenant utiliser la référence principale que vous venez de créer à la place de l'empreinte SHA-1 dans vos commandes Git :
$ git log --pretty=oneline master
1a410efbd13591db07496601ebc7a059dd55cfe9 third commit
cac0cab538b970a37ea1e769cbbde608743bc96d second commit
fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commitIl n'est pas conseillé d'éditer directement les fichiers des références. Git propose une manière sûre de mettre à jour une référence, c'est la commande update-ref :
$ git update-ref refs/heads/master 1a410efbd13591db07496601ebc7a059dd55cfe9C'est simplement ce qu'est une branche dans Git : un simple pointeur ou référence sur le dernier état d'une suite de travaux. Pour créer une branche à partir du deuxième commit, vous pouvez faire ceci :
$ git update-ref refs/heads/test cac0caCette branche contiendra seulement le travail effectué jusqu'à ce commit :
$ git log --pretty=oneline test
cac0cab538b970a37ea1e769cbbde608743bc96d second commit
fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commitLa base de données Git ressemble maintenant à quelque chose comme la Figure 9-4.
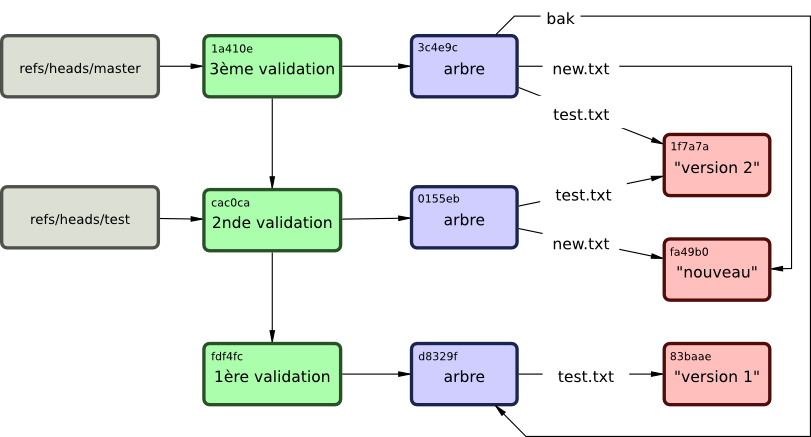
Quand on exécute une commande comme git branch (nomdebranche), Git exécute simplement la commande update-ref pour ajouter l'empreinte SHA-1 du dernier commit dans la référence que l'on veut créer.
IX-C-1. La branche HEAD▲
On peut se poser la question : Comment Git peut avoir connaissance de l'empreinte SHA-1 du dernier commit quand on exécute git branch (branchname) ? La réponse est dans le fichier HEAD (qui veut dire tête en français, soit, ici, l'état courant). Le fichier HEAD est une référence symbolique à la branche courante. Par référence symbolique, j'entends que contrairement à une référence normale, elle ne contient pas une empreinte SHA-1, mais plutôt un pointeur vers une autre référence. Si vous regardez ce fichier, vous devriez voir quelque chose comme ceci :
$ cat .git/HEAD
ref: refs/heads/masterSi vous exécutez git checkout test, Git met à jour ce fichier, qui ressemblera à ceci :
$ cat .git/HEAD
ref: refs/heads/testQuand vous exécutez git commit, il crée l'objet commit en spécifiant le parent du commit comme étant l'empreinte SHA-1 pointé par la référence du fichier HEAD :
On peut éditer manuellement ce fichier, mais encore une fois, il existe une commande supplémentaire pour le faire : symbolic-ref. Vous pouvez lire le contenu de votre fichier HEAD avec cette commande :
$ git symbolic-ref HEAD
refs/heads/masterVous pouvez aussi initialiser la valeur de HEAD :
$ git symbolic-ref HEAD refs/heads/test
$ cat .git/HEAD
ref: refs/heads/testVous ne pouvez pas initialiser une référence symbolique à une valeur non contenue dans refs :
$ git symbolic-ref HEAD test
fatal: Refusing to point HEAD outside of refs/IX-C-2. Étiquettes▲
Nous venons de parcourir les trois types d'objets utilisés par Git, mais il existe un quatrième objet. L'objet étiquette (tag en anglais) ressemble beaucoup à un objet commit. Il contient un étiqueteur, une date, un message et un pointeur. La principale différence est que l'étiquette pointe vers un commit plutôt qu'un arbre. C'est comme une référence à une branche, mais elle ne bouge jamais : elle pointe toujours vers le même commit, lui donnant un nom plus sympathique.
Comme présenté au chapitre 2, il existe deux types d'étiquettes : annotée et légère. Vous pouvez créer une étiquette légère comme ceci :
$ git update-ref refs/tags/v1.0 cac0cab538b970a37ea1e769cbbde608743bc96dC'est tout ce qu'est une étiquette légère : une branche qui n'est jamais modifiée. Une étiquette annotée est plus complexe. Quand on crée une étiquette annotée, Git crée un objet étiquette, puis enregistre une référence qui pointe vers lui plutôt que directement vers le commit. Vous pouvez voir ceci en créant une étiquette annotée (-a spécifie que c'est une étiquette annotée) :
$ git tag -a v1.1 1a410efbd13591db07496601ebc7a059dd55cfe9 ?m 'test tag'Voici l'empreinte SHA-1 de l'objet créé :
$ cat .git/refs/tags/v1.1
9585191f37f7b0fb9444f35a9bf50de191beadc2Exécutez ensuite, la commande cat-file sur l'empreinte SHA-1 :
$ git cat-file -p 9585191f37f7b0fb9444f35a9bf50de191beadc2
object 1a410efbd13591db07496601ebc7a059dd55cfe9
type commit
tag v1.1
tagger Scott Chacon <schacon@gmail.com> Sat May 23 16:48:58 2009 -0700
test tagRemarquez que le contenu de l'objet pointe vers l'empreinte SHA-1 du commit que vous avez étiqueté. Remarquez qu'il n'est pas nécessaire qu'il pointe vers un commit. On peut étiqueter n'importe quel objet. Par exemple, dans le code source de Git, le mainteneur a ajouté ses clés GPG dans un blob et l'a étiqueté. Vous pouvez voir la clé publique en exécutant :
$ git cat-file blob junio-gpg-pubdans le code source de Git. Le noyau Linux contient aussi une étiquette ne pointant pas vers un commit : la première étiquette créée pointe vers l'arbre initial lors de l'importation du code source.
IX-C-3. Références distantes▲
Le troisième type de références que l'on étudiera sont les références distantes (N.d.T remotes). Si l'on ajoute une référence distante et que l'on pousse des objets vers elle, Git stocke la valeur que vous avez poussée en dernière vers cette référence pour chaque branche dans le répertoire refs/remotes. Vous pouvez par exemple, ajouter une référence distante nommée origin et y pousser votre branche master :
$ git remote add origin git@github.com:schacon/simplegit-progit.git
$ git push origin master
Counting objects: 11, done.
Compressing objects: 100% (5/5), done.
Writing objects: 100% (7/7), 716 bytes, done.
Total 7 (delta 2), reused 4 (delta 1)
To git@github.com:schacon/simplegit-progit.git
a11bef0..ca82a6d master -> masterEnsuite, vous pouvez voir l'état de la branche master dans la référence distante origin la dernière fois que vous avez communiqué avec le serveur en regardant le fichier refs/remotes/origin/master :
$ cat .git/refs/remotes/origin/master
ca82a6dff817ec66f44342007202690a93763949Les références distantes diffèrent des branches (références refs/heads) principalement parce qu'on ne peut pas les récupérer dans le répertoire de travail. Git les modifie comme des marque-pages du dernier état de ces branches sur le serveur.
IX-D. Fichiers groupés▲
Revenons à la base de données d'objet de notre dépôt Git de test. Pour l'instant, elle contient 11 objets : 4 blobs, 3 arbres, 3 commits et 1 tag :
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # arbre 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # arbre 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/95/85191f37f7b0fb9444f35a9bf50de191beadc2 # tag
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # arbre 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1Git compresse le contenu de ces fichiers avec zlib et on ne stocke pas grand-chose, finalement, tous ces fichiers occupent seulement 925 octets. Ajoutons de plus gros contenus au dépôt pour montrer une fonctionnalité intéressante de Git. Ajoutez le fichier repo.rb de la bibliothèque Grit que vous avez manipulé plus tôt. Il représente environ 12Ko de code source :
$ curl http://github.com/mojombo/grit/raw/master/lib/grit/repo.rb > repo.rb
$ git add repo.rb
$ git commit -m 'added repo.rb'
[master 484a592] added repo.rb
3 files changed, 459 insertions(+), 2 deletions(-)
delete mode 100644 bak/test.txt
create mode 100644 repo.rb
rewrite test.txt (100%)Si vous observez l'arbre qui en résulte, vous verrez l'empreinte SHA-1 du blob contenant le fichier repo.rb :
$ git cat-file -p master^{tree}
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 9bc1dc421dcd51b4ac296e3e5b6e2a99cf44391e repo.rb
100644 blob e3f094f522629ae358806b17daf78246c27c007b test.txtVous pouvez utilisez git cat-file pour connaître la taille de l'objet :
$ git cat-file -s 9bc1dc421dcd51b4ac296e3e5b6e2a99cf44391e
12898Maintenant, modifiez le fichier un peu et voyez ce qui arrive :
$ echo '# testing' >> repo.rb
$ git commit -am 'modified repo a bit'
[master ab1afef] modified repo a bit
1 files changed, 1 insertions(+), 0 deletions(-)Regardez l'arbre créé par ce commit et vous verrez quelque chose d'intéressant :
$ git cat-file -p master^{tree}
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 05408d195263d853f09dca71d55116663690c27c repo.rb
100644 blob e3f094f522629ae358806b17daf78246c27c007b test.txtCe blob est un blob différent. Bien que l'on ait ajouté une seule ligne à la fin d'un fichier en faisant 400, Git enregistre ce nouveau contenu dans un objet totalement différent :
$ git cat-file -s 05408d195263d853f09dca71d55116663690c27c
12908Il y a donc deux objets de 12Ko quasiment identiques sur le disque. Ne serait-ce pas bien si Git pouvait enregistrer qu'un objet en entier, le deuxième n'étant qu'un delta (une différence) avec le premier ?
Il se trouve que c'est possible. Le format initial dans lequel Git enregistre les objets sur le disque est appelé le format brut (“loose object?). De temps en temps, Git compacte plusieurs de ces objets en un seul fichier binaire appelé packfile (fichier groupé), afin d'économiser de l'espace et d'être plus efficace. Git effectue cette opération quand il y a trop d'objets au format brut, ou si l'on exécute manuellement la commande git gc, ou encore quand on pousse vers un serveur distant. Pour voir cela en action, vous pouvez demander manuellement à Git de compacter les objets en exécutant la commande git gc :
$ git gc
Counting objects: 17, done.
Delta compression using 2 threads.
Compressing objects: 100% (13/13), done.
Writing objects: 100% (17/17), done.
Total 17 (delta 1), reused 10 (delta 0)Si l'on jette un ?il dans le répertoire des objets, on constatera que la plupart des objets ne sont plus là et qu'un couple de fichiers est apparu :
$ find .git/objects -type f
.git/objects/71/08f7ecb345ee9d0084193f147cdad4d2998293
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
.git/objects/info/packs
.git/objects/pack/pack-7a16e4488ae40c7d2bc56ea2bd43e25212a66c45.idx
.git/objects/pack/pack-7a16e4488ae40c7d2bc56ea2bd43e25212a66c45.packLes objets restants sont des blobs qui ne sont pointés par aucun commit. Dans notre cas, il s'agit des blobs “what is up, doc?? et “test content? créés plus tôt comme exemple. Puisqu'ils n'ont été ajoutés à aucun commit, ils sont considérés en suspens et ne sont pas compactés dans le nouveau fichier groupé.
Les autres fichiers sont le nouveau fichier groupé et un index. Le fichier groupé est un fichier unique rassemblant le contenu de tous les objets venant d'être supprimés du système de fichier. L'index est un fichier contenant les emplacements dans le fichier groupé, pour que l'on puisse accéder rapidement à un objet particulier. Ce qui est vraiment bien, c'est que les objets occupaient environ 12Ko d'espace disque avant gc et que le nouveau fichier groupé en occupe seulement 6Ko. On a divisé par deux l'occupation du disque en regroupant les objets.
Comment Git réalise-t-il cela ? Quand Git compacte des objets, il recherche les fichiers qui ont des noms et des tailles similaires, puis enregistre seulement les deltas entre une version du fichier et la suivante. On peut regarder à l'intérieur du fichier groupé et voir l'espace économisé par Git. La commande de plomberie git verify-pack vous permet de voir ce qui a été compacté :
$ git verify-pack -v \
.git/objects/pack/pack-7a16e4488ae40c7d2bc56ea2bd43e25212a66c45.idx
0155eb4229851634a0f03eb265b69f5a2d56f341 tree 71 76 5400
05408d195263d853f09dca71d55116663690c27c blob 12908 3478 874
09f01cea547666f58d6a8d809583841a7c6f0130 tree 106 107 5086
1a410efbd13591db07496601ebc7a059dd55cfe9 commit 225 151 322
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a blob 10 19 5381
3c4e9cd789d88d8d89c1073707c3585e41b0e614 tree 101 105 5211
484a59275031909e19aadb7c92262719cfcdf19a commit 226 153 169
83baae61804e65cc73a7201a7252750c76066a30 blob 10 19 5362
9585191f37f7b0fb9444f35a9bf50de191beadc2 tag 136 127 5476
9bc1dc421dcd51b4ac296e3e5b6e2a99cf44391e blob 7 18 5193 1
05408d195263d853f09dca71d55116663690c27c \
ab1afef80fac8e34258ff41fc1b867c702daa24b commit 232 157 12
cac0cab538b970a37ea1e769cbbde608743bc96d commit 226 154 473
d8329fc1cc938780ffdd9f94e0d364e0ea74f579 tree 36 46 5316
e3f094f522629ae358806b17daf78246c27c007b blob 1486 734 4352
f8f51d7d8a1760462eca26eebafde32087499533 tree 106 107 749
fa49b077972391ad58037050f2a75f74e3671e92 blob 9 18 856
fdf4fc3344e67ab068f836878b6c4951e3b15f3d commit 177 122 627
chain length = 1: 1 object
pack-7a16e4488ae40c7d2bc56ea2bd43e25212a66c45.pack: okSi on se souvient bien, le blob 9bc1d, qui est la première version de fichier repo.rb file, référence le blob 05408, qui est la seconde version du fichier. La troisième colonne de l'affichage est la taille de l'objet dans le fichier compact et on peut voir que 05408 occupe 12Ko dans le fichier, mais que 9bc1d occupe seulement 7 octets. Ce qui est aussi intéressant est que la seconde version du fichier est celle qui est enregistrée telle quelle, tandis que la version originale est enregistrée sous forme d'un delta. La raison en est que vous aurez sans doute besoin d'accéder rapidement aux versions les plus récentes du fichier.
Une chose intéressante à propos de ceci est que l'on peut recompacter à tout moment. Git recompacte votre base de données occasionnellement, en essayant d'économiser de la place. Vous pouvez aussi recompacter à la main, en exécutant la commande git gc vous-même.
IX-E. Les références spécifiques▲
Dans tout le livre, nous avons utilisé des associations simples entre les branches distantes et les références locales. Elles peuvent être plus complexes. Supposons que vous ajoutiez un dépôt distant comme ceci :
$ git remote add origin git@github.com:schacon/simplegit-progit.gitCela ajoute une section au fichier .git/config, contenant le nom du dépôt distant (origin), l'URL de ce dépôt et la spécification des références pour la récupération :
[remote "origin"]
url = git@github.com:schacon/simplegit-progit.git
fetch = +refs/heads/*:refs/remotes/origin/*Le format d'une spécification de référence est un + facultatif, suivi de <src>:<dst>, où <src> est le motif des références du côté distant et <dst> est l'emplacement local où les références seront enregistrées. Le + précise à Git de mettre à jour la référence même si ce n'est pas une avance rapide.
Dans le cas par défaut, qui est celui d'un enregistrement automatique par la commande git remote add, Git récupère toutes les références de refs/heads/ sur le serveur et les enregistre localement dans refs/remotes/origin/. Ainsi, s'il y a une branche master sur le serveur, vous pouvez accéder localement à l'historique de cette branche via :
$ git log origin/master
$ git log remotes/origin/master
$ git log refs/remotes/origin/masterCes syntaxes sont toutes équivalentes, car Git les développe en refs/remotes/origin/master.
Si vous préférez que Git récupère seulement la branche master et non chacune des branches du serveur distant, vous pouvez remplacer la ligne fetch par :
fetch = +refs/heads/master:refs/remotes/origin/masterC'est la spécification des références de git fetch pour ce dépôt distant. Si l'on veut effectuer une action particulière une seule fois, la spécification des références peut aussi être précisée en ligne de commande. Pour retirer la branche master du dépôt distant vers la branche locale origin/mymaster, vous pouvez exécuter :
$ git fetch origin master:refs/remotes/origin/mymasterVous pouvez indiquer des spécifications pour plusieurs références. En ligne de commande, vous pouvez tirer plusieurs branches de cette façon :
$ git fetch origin master:refs/remotes/origin/mymaster \
topic:refs/remotes/origin/topic
From git@github.com:schacon/simplegit
! [rejected] master -> origin/mymaster (non fast forward)
* [new branch] topic -> origin/topicDans ce cas, la récupération /* pull / de la branche master a été refusée, car ce n'était pas une avance rapide. On peut surcharger ce comportement en précisant un + devant la spécification de la référence.
On peut aussi indiquer plusieurs spécifications de référence pour la récupération, dans le fichier de configuration. Si vous voulez toujours récupérer les branches master et experiment, ajoutez ces deux lignes :
[remote "origin"]
url = git@github.com:schacon/simplegit-progit.git
fetch = +refs/heads/master:refs/remotes/origin/master
fetch = +refs/heads/experiment:refs/remotes/origin/experimentVous ne pouvez pas utiliser des jokers partiels, ce qui suit est donc invalide :
fetch = +refs/heads/qa*:refs/remotes/origin/qa*On peut toutefois utiliser des espaces de noms pour accomplir cela. S'il existe une équipe qualité (QA) qui publie une série de branches et que l'on veut la branche master, les branches de l'équipe qualité et rien d'autre, on peut utiliser la configuration suivante :
[remote "origin"]
url = git@github.com:schacon/simplegit-progit.git
fetch = +refs/heads/master:refs/remotes/origin/master
fetch = +refs/heads/qa/*:refs/remotes/origin/qa/*Si vous utilisez des processus complexes impliquant une équipe qualité, des développeurs et des intégrateurs qui publient des branches et qui collaborent sur des branches distantes, vous pouvez facilement utiliser des espaces des noms de cette façon.
IX-E-1. Publier une référence spécifique▲
Il est pratique de pouvoir récupérer des références issues d'espace de nom de cette façon, mais comment l'équipe qualité insère-t-elle ces branches dans l'espace de nom qa/ en premier lieu ? On peut accomplir cela en utilisant les spécifications de références pour la publication.
Si l'équipe qualité veut publier sa branche master vers qa/master sur le serveur distant, elle peut exécuter :
$ git push origin master:refs/heads/qa/masterSi elle veut que Git le fasse automatiquement à chaque exécution de git push origin, elle peut ajouter une entrée push au fichier de configuration :
[remote "origin"]
url = git@github.com:schacon/simplegit-progit.git
fetch = +refs/heads/*:refs/remotes/origin/*
push = refs/heads/master:refs/heads/qa/masterDe même, cela fera que, par défaut, git push origin publiera la branche locale master sur la branche distante qa/master.
IX-E-2. Supprimer des références▲
Vous pouvez aussi utiliser les spécifications de références pour supprimer des références sur le serveur distant en exécutant une commande comme :
$ git push origin :topicLa spécification de référence ressemble à <src>:<dst>, mais en laissant vide la partie <src>, cela signifie une création de la branche à partir de rien et donc sa suppression.
IX-F. Protocoles de transfert▲
Git peut transférer des données entre deux dépôts, de deux façons principales : via HTTP et via un protocole dit “intelligent? utilisé par les transports file://, ssh:// et git://. Cette section fait un tour d'horizon du fonctionnement de ces deux protocoles.
IX-F-1. Protocole stupide▲
On parle souvent du transfert Git sur HTTP comme étant un protocole stupide, car il ne nécessite aucun code spécifique à Git côté serveur durant le transfert. Le processus de récupération est une série de requêtes GET, où le client devine la structure du dépôt Git présent sur le serveur. Suivons le processus http-fetch pour la bibliothèque simplegit :
$ git clone http://github.com/schacon/simplegit-progit.gitLa première chose que fait cette commande est de récupérer le fichier info/refs. Ce fichier est écrit par la commande update-server-info et c'est pour cela qu'il faut activer le hook postreceive, sinon le transfert HTTP ne fonctionnera pas correctement :
=> GET info/refs
ca82a6dff817ec66f44342007202690a93763949 refs/heads/masterOn possède maintenant une liste des références distantes et empreintes SHA1. Ensuite, on regarde vers quoi pointe HEAD, pour savoir sur quelle branche se placer quand on aura fini :
=> GET HEAD
ref: refs/heads/masterOn aura besoin de se placer sur la branche master, quand le processus sera terminé. On est maintenant prêt à démarrer le processus de parcours. Puisque votre point de départ est l'objet commit ca82a6 que vous avez vu dans le fichier info/refs, vous commencez par le récupérer :
=> GET objects/ca/82a6dff817ec66f44342007202690a93763949
(179 bytes of binary data)Vous obtenez un objet, cet objet est dans le format brut sur le serveur et vous l'avez récupéré à travers une requête HTTP GET statique. Vous pouvez le décompresser avec zlib, ignorer l'en-tête et regarder le contenu du commit :
$ git cat-file -p ca82a6dff817ec66f44342007202690a93763949
tree cfda3bf379e4f8dba8717dee55aab78aef7f4daf
parent 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
author Scott Chacon <schacon@gmail.com> 1205815931 -0700
committer Scott Chacon <schacon@gmail.com> 1240030591 -0700
changed the version numberPuis, vous avez deux autres objets supplémentaires à récupérer : cfda3b qui est l'arbre du contenu sur lequel pointe le commit que nous venons de récupérer et 085bb3 qui est le commit parent :
=> GET objects/08/5bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
(179 bytes of data)Cela vous donne l'objet du prochain commit. Récupérez l'objet arbre :
=> GET objects/cf/da3bf379e4f8dba8717dee55aab78aef7f4daf
(404 - Not Found)Oups, on dirait que l'objet arbre n'est pas au format brut sur le serveur, vous obtenez donc une réponse 404. On peut en déduire certaines raisons : l'objet peut être dans un dépôt suppléant ou il peut être dans un fichier groupé de ce dépôt. Git vérifie la liste des dépôts suppléants d'abord :
=> GET objects/info/http-alternates
(empty file)Si la réponse contenait une liste d'URL suppléantes, Git aurait cherché les fichiers bruts et les fichiers groupés à ces emplacements, c'est un mécanisme sympathique pour les projets qui ont dérivé d'un autre pour partager les objets sur le disque. Cependant, puisqu'il n'y a pas de suppléants listés dans ce cas, votre objet doit se trouver dans un fichier groupé. Pour voir quels fichiers groupés sont disponibles sur le serveur, vous avez besoin de récupérer le fichier objects/info/packs, qui en contient la liste (générée également par update-server-info) :
=> GET objects/info/packs
P pack-816a9b2334da9953e530f27bcac22082a9f5b835.packIl n'existe qu'un seul fichier groupé sur le serveur, votre objet se trouve évidemment dedans, mais vous allez tout de même vérifier l'index pour être sûr. C'est également utile lorsque vous avez plusieurs fichiers groupés sur le serveur, vous pouvez donc voir quel fichier groupé contient l'objet dont vous avez besoin :
=> GET objects/pack/pack-816a9b2334da9953e530f27bcac22082a9f5b835.idx
(4k of binary data)Maintenant que vous avez l'index du fichier groupé, vous pouvez vérifier si votre objet est bien dedans, car l'index liste les empreintes SHA-1 des objets contenus dans ce fichier groupé et des emplacements de ces objets. Votre objet est là, allez donc récupérer le fichier groupé complet :
=> GET objects/pack/pack-816a9b2334da9953e530f27bcac22082a9f5b835.pack
(13k of binary data)Vous avez votre objet arbre, vous continuez donc le chemin des commits. Ils sont également tous contenus dans votre fichier groupé que vous venez de télécharger, vous n'avez donc pas d'autres requêtes à faire au serveur. Git récupère une copie de travail de votre branche master qui été référencée par HEAD que vous avez téléchargé au début.
La sortie complète de cette procédure ressemble à :
$ git clone http://github.com/schacon/simplegit-progit.git
Initialized empty Git repository in /private/tmp/simplegit-progit/.git/
got ca82a6dff817ec66f44342007202690a93763949
walk ca82a6dff817ec66f44342007202690a93763949
got 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
Getting alternates list for http://github.com/schacon/simplegit-progit.git
Getting pack list for http://github.com/schacon/simplegit-progit.git
Getting index for pack 816a9b2334da9953e530f27bcac22082a9f5b835
Getting pack 816a9b2334da9953e530f27bcac22082a9f5b835
which contains cfda3bf379e4f8dba8717dee55aab78aef7f4daf
walk 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
walk a11bef06a3f659402fe7563abf99ad00de2209e6IX-F-2. Protocole intelligent▲
La méthode HTTP est simple mais un peu inefficace. Utiliser des protocoles intelligents est une méthode plus habituelle pour transférer des données. Ces protocoles ont un exécutable du côté distant qui connaît Git, il peut lire les données locales et deviner ce que le client a ou ce dont il a besoin pour générer des données personnalisées pour lui. Il y a deux ensembles d'exécutables pour transférer les données : une paire pour téléverser des données et une paire pour en télécharger.
IX-F-2-a. Téléverser des données▲
Pour téléverser des données vers un exécutable distant, Git utilise les exécutables send-pack et receive-pack. L'exécutable send-pack tourne sur le client et se connecte à l'exécutable receive-pack du côté serveur.
Par exemple, disons que vous exécutez git push origin master dans votre projet et origin est défini comme une URL qui utilise le protocole SSH. Git appelle l'exécutable send-pack, qui initialise une connexion à travers SSH vers votre serveur. Il essaye d'exécuter une commande sur le serveur distant via un appel SSH qui ressemble à :
$ ssh -x git@github.com "git-receive-pack 'schacon/simplegit-progit.git'"
005bca82a6dff817ec66f4437202690a93763949 refs/heads/master report-status delete-refs
003e085bb3bcb608e1e84b2432f8ecbe6306e7e7 refs/heads/topic
0000La commande git-receive-pack répond immédiatement avec une ligne pour chaque référence qu'elle connaît actuellement, dans ce cas, uniquement la branche master et ses empreintes SHA. La première ligne contient également une liste des compétences du serveur (ici : report-status et delete-refs).
Chaque ligne commence avec une valeur hexadécimale sur 4 octets, spécifiant le reste de la longueur de la ligne. La première ligne, ici, commence avec 005b, soit 91 en hexadécimal, ce qui signifie qu'il y a 91 octets restants sur cette ligne. La ligne suivante commence avec 003e, soit 62, vous lisez donc les 62 octets restants. La ligne d'après est 0000, signifiant que le serveur a fini de lister ses références.
Maintenant que vous connaissez l'état du serveur, votre exécutable send-pack détermine quels commits il a que le serveur n'a pas. L'exécutable send-pack envoie alors à l'exécutable receive-pack, les informations concernant chaque référence que cette commande push va mettre à jour. Par exemple, si vous mettez à jour la branche master et ajoutez la branche experiment, la réponse de send-pack ressemblera à quelque chose comme :
0085ca82a6dff817ec66f44342007202690a93763949 15027957951b64cf874c3557a0f3547bd83b3ff6 refs/heads/master report-status
00670000000000000000000000000000000000000000 cdfdb42577e2506715f8cfeacdbabc092bf63e8d refs/heads/experiment
0000La valeur SHA-1 remplie de ‘0' signifie qu'il n'y avait rien à cet endroit avant, car vous êtes en train d'ajouter la référence experiment. Si vous étiez en train de supprimer une référence, vous verriez l'opposé : que des ‘0' du côté droit.
Git envoie une ligne pour chaque référence que l'on met à jour avec l'ancien SHA, le nouveau SHA et la référence en train d'être mise à jour. La première ligne contient également les compétences du client. Puis, le client téléverse un fichier groupé de tous les objets que le serveur n'a pas encore. Finalement, le serveur répond avec une indication de succès (ou d'échec) :
000Aunpack okIX-F-2-b. Téléchargement des données▲
Lorsque vous téléchargez des données, les exécutables fetch-pack et upload-pack entrent en jeu. Le client initialise un exécutable fetch-pack qui se connecte à un exécutable upload-pack du côté serveur pour négocier quelles données seront remontées.
Il y a plusieurs manières d'initialiser l'exécutable upload-pack sur le dépôt distant. Vous pouvez passer par SSH de la même manière qu'avec l'exécutable receive-pack. Vous pouvez également initialiser l'exécutable à travers le démon Git, qui écoute sur le port 9418 du serveur par défaut. L'exécutable fetch-pack envoie des données qui ressemblent à cela juste après la connexion :
003fgit-upload-pack schacon/simplegit-progit.git\0host=myserver.com\0Cela commence par les 4 octets désignant la quantité de données qui suit, puis la commande à exécuter suivie par un octet nul, puis le nom d'hôte du serveur suivi d'un octet nul final. Le démon Git vérifie que la commande peut être exécutée, que le dépôt existe et est accessible publiquement. Si tout va bien, il appelle l'exécutable upload-pack et lui passe la main.
Si vous êtes en train de tirer (fetch) à travers SSH, fetch-pack exécute plutôt quelque chose du genre :
$ ssh -x git@github.com "git-upload-pack 'schacon/simplegit-progit.git'"Dans tous les cas, après que fetch-pack se connecte, upload-pack lui répond quelque chose du style :
0088ca82a6dff817ec66f44342007202690a93763949 HEAD\0multi_ack thin-pack \
side-band side-band-64k ofs-delta shallow no-progress include-tag
003fca82a6dff817ec66f44342007202690a93763949 refs/heads/master
003e085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7 refs/heads/topic
0000C'est très proche de ce que répondait receive-pack mais les compétences sont différentes. En plus, il vous répond la référence HEAD, afin que le client sache quoi récupérer dans le cas d'un clone.
À ce moment, l'exécutable fetch-pack regarde quels objets il a et répond avec les objets dont il a besoin en envoyant “want? (vouloir) suivi du SHA qu'il veut. Il envoie tous les objets qu'il a déjà avec “have? suivi du SHA. À la fin de la liste, il écrit “done? pour initialiser l'exécutable upload-pack à commencer à envoyer le fichier groupé des données demandées :
0054want ca82a6dff817ec66f44342007202690a93763949 ofs-delta
0032have 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
0000
0009doneC'est le cas basique d'un protocole de transfert. Dans des cas plus complexes, le client a des compétences multi_ack (plusieurs réponses) ou side-band (plusieurs connexions), mais cet exemple vous montre les bases du protocole intelligent.
IX-G. Maintenance et récupération de données▲
Parfois, vous aurez besoin de faire un peu de ménage : faire un dépôt plus compact, nettoyer les dépôts importés, ou récupérer du travail perdu. Cette section couvrira certains de ces scénarios.
IX-G-1. Maintenance▲
De temps en temps, Git exécute automatiquement une commande appelée “auto gc?. La plupart du temps, cette commande ne fait rien. Cependant, s'il y a trop d'objets bruts (des objets qui ne sont pas dans des fichiers groupés), ou trop de fichiers groupés, Git lance une commande git gc à part entière. gc est l'abréviation pour “garbage collect? (ramasse-miettes) et la commande fait plusieurs choses : elle rassemble plusieurs objets bruts et les place dans un fichier groupé, elle consolide des fichiers groupés en un gros fichier groupé et elle supprime des objets qui ne sont plus accessibles depuis un commit et qui sont vieux de plusieurs mois.
Vous pouvez exécuter auto gc manuellement :
$ git gc --autoEncore une fois, cela ne fait généralement rien. Vous devez avoir environ 7.000 objets bruts ou plus de 50 fichiers groupés pour que Git appelle une vraie commande gc. Vous pouvez modifier ces limites avec les propriétés de configuration gc.auto et gc.autopacklimit, respectivement.
gc regroupera aussi vos références dans un seul fichier. Supposons que votre dépôt contienne les branches et étiquettes suivantes :
$ find .git/refs -type f
.git/refs/heads/experiment
.git/refs/heads/master
.git/refs/tags/v1.0
.git/refs/tags/v1.1Si vous exécutez git gc, vous n'aurez plus ces fichiers dans votre répertoire refs. Git les déplacera pour le bien de l'efficacité dans un fichier nommé .git/packed-refs qui ressemble à ceci :
$ cat .git/packed-refs
# pack-refs with: peeled
cac0cab538b970a37ea1e769cbbde608743bc96d refs/heads/experiment
ab1afef80fac8e34258ff41fc1b867c702daa24b refs/heads/master
cac0cab538b970a37ea1e769cbbde608743bc96d refs/tags/v1.0
9585191f37f7b0fb9444f35a9bf50de191beadc2 refs/tags/v1.1
^1a410efbd13591db07496601ebc7a059dd55cfe9Si vous mettez à jour une référence, Git ne modifiera pas ce fichier, mais enregistrera plutôt un nouveau fichier dans refs/heads. Pour obtenir l'empreinte SHA approprié pour référence donnée, Git cherche d'abord cette référence dans le répertoire refs, puis dans le fichier packed-refs si non trouvée. Cependant, si vous ne pouvez pas trouver une référence dans votre répertoire refs, elle est probablement dans votre fichier packed-refs.
Remarquez la dernière ligne du fichier, celle commençant par ^. Cela signifie que l'étiquette directement au-dessus est une étiquette annotée et que cette ligne est le commit que l'étiquette annotée référence.
IX-G-2. Récupération de données▲
À un moment quelconque de votre vie avec Git, vous pouvez accidentellement perdre un commit. Généralement, cela arrive parce que vous avez forcé la suppression d'une branche contenant du travail et il se trouve que vous voulez cette branche finalement; ou vous avez réinitialisé une branche avec suppression, en abandonnant des commits dont vous vouliez des informations. Supposons que cela arrive, comment pouvez-vous récupérer vos commits ?
Voici un exemple qui réinitialise la branche master avec suppression dans votre dépôt de test vers un ancien commit et qui récupère les commits perdus. Premièrement, vérifions dans quel état est votre dépôt en ce moment :
$ git log --pretty=oneline
ab1afef80fac8e34258ff41fc1b867c702daa24b modified repo a bit
484a59275031909e19aadb7c92262719cfcdf19a added repo.rb
1a410efbd13591db07496601ebc7a059dd55cfe9 third commit
cac0cab538b970a37ea1e769cbbde608743bc96d second commit
fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commitMaintenant, déplaçons la branche master vers le commit du milieu :
$ git reset --hard 1a410efbd13591db07496601ebc7a059dd55cfe9
HEAD is now at 1a410ef third commit
$ git log --pretty=oneline
1a410efbd13591db07496601ebc7a059dd55cfe9 third commit
cac0cab538b970a37ea1e769cbbde608743bc96d second commit
fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commitVous avez effectivement perdu les deux commits du haut, vous n'avez pas de branche depuis laquelle ces commits seraient accessibles. Vous avez besoin de trouver le SHA du dernier commit et d'ajouter une branche s'y référant. Le problème est de trouver ce SHA, ce n'est pas comme si vous l'aviez mémorisé, hein ?
Souvent, la manière la plus rapide est d'utiliser l'outil git reflog Pendant que vous travaillez, Git enregistre l'emplacement de votre HEAD chaque fois que vous le changez. À chaque commit ou commutation de branche, le journal des références (reflog) est mis à jour. Le journal des références est aussi mis à jour par la commande git update-ref, qui est une autre raison de l'utiliser plutôt que de simplement écrire votre valeur SHA dans vos fichiers de références, comme mentionné dans la section “Git References? plus haut dans ce chapitre. Vous pouvez voir où vous étiez à n'importe quel moment en exécutant git reflog :
$ git reflog
1a410ef HEAD@{0}: 1a410efbd13591db07496601ebc7a059dd55cfe9: updating HEAD
ab1afef HEAD@{1}: ab1afef80fac8e34258ff41fc1b867c702daa24b: updating HEADIci, nous pouvons voir deux commits que nous avons récupérés, cependant, il n'y a pas plus d'information ici. Pour voir, les mêmes informations d'une manière plus utile, nous pouvons exécuter git log -g, qui nous donnera une sortie normalisée pour votre journal de références :
$ git log -g
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Reflog: HEAD@{0} (Scott Chacon <schacon@gmail.com>)
Reflog message: updating HEAD
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:22:37 2009 -0700
third commit
commit ab1afef80fac8e34258ff41fc1b867c702daa24b
Reflog: HEAD@{1} (Scott Chacon <schacon@gmail.com>)
Reflog message: updating HEAD
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
modified repo a bitOn dirait que le commit du bas est celui que vous avez perdu, vous pouvez donc le récupérer en créant une nouvelle branche sur ce commit. Par exemple, vous créez une branche nommée recover-branch au commit (ab1afef):
$ git branch recover-branch ab1afef
$ git log --pretty=oneline recover-branch
ab1afef80fac8e34258ff41fc1b867c702daa24b modified repo a bit
484a59275031909e19aadb7c92262719cfcdf19a added repo.rb
1a410efbd13591db07496601ebc7a059dd55cfe9 third commit
cac0cab538b970a37ea1e769cbbde608743bc96d second commit
fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commitSuper, maintenant vous avez une nouvelle branche appelée recover-branch à l'emplacement où votre branche master se trouvait, faisant en sorte que les deux premiers commits soit à nouveau accessibles.
Pour poursuivre, nous supposerons que vos pertes ne sont pas dans le journal des références pour une raison quelconque. On peut simuler cela en supprimant recover-branch et le journal des références. Maintenant, les deux premiers commits ne sont plus accessibles (encore) :
$ git branch ?D recover-branch
$ rm -Rf .git/logs/Puisque les données du journal de référence sont sauvegardées dans le répertoire .git/logs/, vous n'avez effectivement plus de journal de références. Comment pouvez-vous récupérer ces commits maintenant ? Une manière de faire est d'utiliser l'outil git fsck, qui vérifie l'intégrité de votre base de données. Si vous l'exécutez avec l'option --full, il vous montre tous les objets qui ne sont pas référencés par d'autres objets :
$ git fsck --full
dangling blob d670460b4b4aece5915caf5c68d12f560a9fe3e4
dangling commit ab1afef80fac8e34258ff41fc1b867c702daa24b
dangling tree aea790b9a58f6cf6f2804eeac9f0abbe9631e4c9
dangling blob 7108f7ecb345ee9d0084193f147cdad4d2998293Dans ce cas, vous pouvez voir votre commit manquant après “dangling commit?. Vous pouvez le restaurer de la même manière que précédemment, en créant une branche qui référence cette empreinte SHA.
IX-G-3. Suppression d'objets▲
Il y a beaucoup de choses dans Git qui sont géniales, mais une fonctionnalité qui peut poser problème est le fait que git clone télécharge l'historique entier du projet, incluant chaque version de chaque fichier. C'est très bien lorsque le tout est du code source, parce Git est hautement optimisé pour compresser les données efficacement. Cependant, si quelqu'un à un moment donné de l'historique de votre projet a ajouté un énorme fichier, chaque clone sera forcé de télécharger cet énorme fichier, même s'il a été supprimé du projet dans le commit suivant. Puisqu'il est accessible depuis l'historique, il sera toujours là.
Cela peut être un énorme problème, lorsque vous convertissez un dépôt Subversion ou Perforce en un dépôt Git. Car, comme vous ne téléchargez pas l'historique entier dans ces systèmes, ce genre d'ajout n'a que peu de conséquences. Si vous avez importé depuis un autre système ou que votre dépôt est beaucoup plus gros que ce qu'il devrait être, voici comment vous pouvez trouver et supprimer des gros objets.
Soyez prévenu : cette technique détruit votre historique de commit. Elle réécrit chaque objet commit depuis le premier objet arbre que vous modifiez pour supprimer une référence d'un gros fichier. Si vous faites cela immédiatement après un import, avant que quiconque n'ait eu le temps de commencer à travailler sur ce commit, tout va bien. Sinon, vous devez alerter tous les contributeurs qu'ils doivent recommencer (ou au moins faire un rebase) sur votre nouveau commit.
Pour la démonstration, nous allons ajouter un gros fichier dans votre dépôt de test, le supprimer dans le commit suivant, le trouver et le supprimer de manière permanente du dépôt. Premièrement, ajoutons un gros objet à votre historique :
$ curl http://kernel.org/pub/software/scm/git/git-1.6.3.1.tar.bz2 > git.tbz2
$ git add git.tbz2
$ git commit -am 'added git tarball'
[master 6df7640] added git tarball
1 files changed, 0 insertions(+), 0 deletions(-)
create mode 100644 git.tbz2Oups, vous ne vouliez pas rajouter une énorme archive à votre projet. Il vaut mieux s'en débarrasser :
$ git rm git.tbz2
rm 'git.tbz2'
$ git commit -m 'oops - removed large tarball'
[master da3f30d] oops - removed large tarball
1 files changed, 0 insertions(+), 0 deletions(-)
delete mode 100644 git.tbz2Maintenant, faites un gc sur votre base de données, pour voir combien d'espace disque vous utilisez :
$ git gc
Counting objects: 21, done.
Delta compression using 2 threads.
Compressing objects: 100% (16/16), done.
Writing objects: 100% (21/21), done.
Total 21 (delta 3), reused 15 (delta 1)Vous pouvez exécuter la commande count-objects pour voir rapidement combien d'espace disque vous utilisez :
$ git count-objects -v
count: 4
size: 16
in-pack: 21
packs: 1
size-pack: 2016
prune-packable: 0
garbage: 0L'entrée size-pack est la taille de vos fichiers groupés en kilo-octets, vous utilisez donc 2Mo. Avant votre dernier commit, vous utilisiez environ 2Ko, clairement, supprimer le fichier avec le commit précédent ne l'a pas enlevé de votre historique. À chaque fois que quelqu'un clonera votre dépôt, il aura à cloner les 2Mo pour récupérer votre tout petit projet, parce que vous avez accidentellement rajouté un gros fichier. Débarassons-nous-en.
Premièrement, vous devez le trouver. Dans ce cas, vous savez déjà de quel fichier il s'agit. Mais supposons que vous ne le sachiez pas, comment identifieriez-vous quel(s) fichier(s) prennent trop de place ? Si vous exécutez git gc, tous les objets sont dans des fichiers groupés ; vous pouvez identifier les gros objets en utilisant une autre commande de plomberie appelée git verify-pack et en triant sur le troisième champ de la sortie qui est la taille des fichiers. Vous pouvez également le faire suivre à la commande tail, car vous ne vous intéressez qu'aux fichiers les plus gros :
$ git verify-pack -v .git/objects/pack/pack-3f8c0...bb.idx | sort -k 3 -n | tail -3
e3f094f522629ae358806b17daf78246c27c007b blob 1486 734 4667
05408d195263d853f09dca71d55116663690c27c blob 12908 3478 1189
7a9eb2fba2b1811321254ac360970fc169ba2330 blob 2056716 2056872 5401Le gros objet est à la fin : 2Mo. Pour trouver quel fichier c'est, vous allez utiliser la commande rev-list, que vous avez utilisée brièvement dans le chapitre 7. Si vous mettez l'option --objects à rev-list, elle listera tous les SHA des commits et des blobs avec le chemin du fichier associés. Vous pouvez utiliser cette commande pour trouver le nom de votre blob :
$ git rev-list --objects --all | grep 7a9eb2fb
7a9eb2fba2b1811321254ac360970fc169ba2330 git.tbz2Maintenant, vous voulez supprimer ce fichier de toutes les arborescences passées. Vous pouvez facilement voir quels commits ont modifié ce fichier :
$ git log --pretty=oneline -- git.tbz2
da3f30d019005479c99eb4c3406225613985a1db oops - removed large tarball
6df764092f3e7c8f5f94cbe08ee5cf42e92a0289 added git tarballVous devez réécrire tous les commits qui sont liés à 6df76 pour supprimer totalement ce fichier depuis votre historique Git. Pour cela, utilisez filter-branch, que vous avez utilisé dans le Chapitre 6 :
$ git filter-branch --index-filter \
'git rm --cached --ignore-unmatch git.tbz2' -- 6df7640^..
Rewrite 6df764092f3e7c8f5f94cbe08ee5cf42e92a0289 (1/2)rm 'git.tbz2'
Rewrite da3f30d019005479c99eb4c3406225613985a1db (2/2)
Ref 'refs/heads/master' was rewrittenL'option --index-filter est similaire à l'option --tree-filter utilisé dans le Chapitre 6, sauf qu'au lieu de modifier les fichiers sur le disque, vous modifiez votre zone d'attente et votre index. Plutôt que de supprimer un fichier spécifique avec une commande comme rm file, vous devez le supprimer avec git rm --cached; vous devez le supprimer de l'index, pas du disque. La raison de faire cela de cette manière est la rapidité, car Git n'ayant pas besoin de récupérer chaque révision sur disque avant votre filtre, la procédure peut être beaucoup beaucoup plus rapide. Vous pouvez faire la même chose avec --tree-filter si vous voulez. L'option --ignore-unmatch de git rm lui dit que ce n'est pas une erreur si le motif que vous voulez supprimez n'existe pas. Finalement, vous demandez à filter-branch de réécrire votre historique seulement depuis le parent du commit 6df7640, car vous savez que c'est de là que le problème a commencé. Sinon, il aurait démarré du début et serait plus long sans nécessité.
Votre historique ne contient plus de référence à ce fichier. Cependant, votre journal de révision et un nouvel ensemble de références que Git a ajouté lors de votre filter-branch dans .git/refs/original en contiennent encore, vous devez donc les supprimer puis regrouper votre base de données. Vous devez vous débarrasser de tout ce qui fait référence à ces vieux commits avant de regrouper :
$ rm -Rf .git/refs/original
$ rm -Rf .git/logs/
$ git gc
Counting objects: 19, done.
Delta compression using 2 threads.
Compressing objects: 100% (14/14), done.
Writing objects: 100% (19/19), done.
Total 19 (delta 3), reused 16 (delta 1)Voyons combien d'espace vous avez récupéré :
$ git count-objects -v
count: 8
size: 2040
in-pack: 19
packs: 1
size-pack: 7
prune-packable: 0
garbage: 0La taille du dépôt regroupé est retombée à 7Ko, ce qui est beaucoup moins que 2Mo. Vous pouvez voir dans la valeur “size? que votre gros objet est toujours dans vos objets bruts, il n'est donc pas parti; mais il ne sera plus transféré lors d'une poussée vers un serveur ou un clone, ce qui est l'important dans l'histoire. Si vous voulez réellement, vous pouvez supprimer complètement l'objet en exécutant git prune --expire.
IX-H. Résumé▲
Vous devriez avoir une plutôt bonne compréhension de ce que Git fait en arrière plan et, à un certain degré, comment c'est implémenté. Ce chapitre a parcouru un certain nombre de commandes de plomberie, commandes qui sont à un niveau plus bas et plus simple que les commandes de porcelaine que vous avez après dans le reste du livre. Comprendre comment Git travaille à bas niveau devrait vous aider à comprendre pourquoi il fait ce qu'il fait et à créer vos propres outils et scripts pour que votre workflow fonctionne comme vous l'entendez.
Git, comme un système de fichiers adressables par contenu est un outil puissant que vous pouvez utiliser pour des fonctionnalités au-delà d'un VCS. J'espère que vous pourrez utilisez votre connaissance nouvellement acquise des tripes de Git pour implémenter votre propre super application de cette technologie et que vous vous sentirez plus à l'aise à utiliser Git de manière plus poussée.
