



III. Les branches avec Git▲
Quasiment tous les VCS ont une forme ou une autre de gestion de branche. Faire une branche signifie diverger de la ligne principale de développement et continuer à travailler sans se préoccuper de cette ligne principale. Dans de nombreux outils de gestion de version, cette fonctionnalité est souvent chère en ressources et nécessite souvent de créer une nouvelle copie du répertoire de travail, ce qui peut prendre longtemps dans le cas de grands projets.
De nombreuses personnes font référence au modèle de gestion de branche de Git comme LA fonctionnalité et c'est sûrement la spécificité de Git par rapport à la communauté des gestionnaires de version. Pourquoi est-elle si spéciale ? La méthode de Git pour gérer les branches est particulièrement légère, permettant de réaliser des embranchements quasi instantanément et de basculer de branche généralement aussi rapidement. À la différence de nombreux autres gestionnaires de version, Git encourage à travailler avec des méthodes qui privilégient la création et la fusion de branches, jusqu'à plusieurs fois par jour. Bien comprendre et maîtriser cette fonctionnalité est un atout pour faire de Git un outil unique qui peut littéralement changer la manière de développer.
III-A. Ce qu'est une branche▲
Pour réellement comprendre comment Git gère les branches, nous devons revenir en arrière et examiner de plus près comment Git stocke ses données. Comme vous pouvez vous en souvenir du chapitre 1, Git ne stocke pas ses données comme une série de changesets ou deltas, mais comme une série d'instantanés.
Lorsqu'on valide dans Git, Git stocke un objet commit qui contient un pointeur vers l'instantané du contenu qui a été indexé, les métadonnées d'auteur et de message et zéro ou plusieurs pointeurs vers le ou les commits qui sont les parents directs de ce commit : zéro parent pour la première validation, un parent pour un commit normal et des parents multiples pour des commits qui sont le résultat de la fusion d'une ou plusieurs branches.
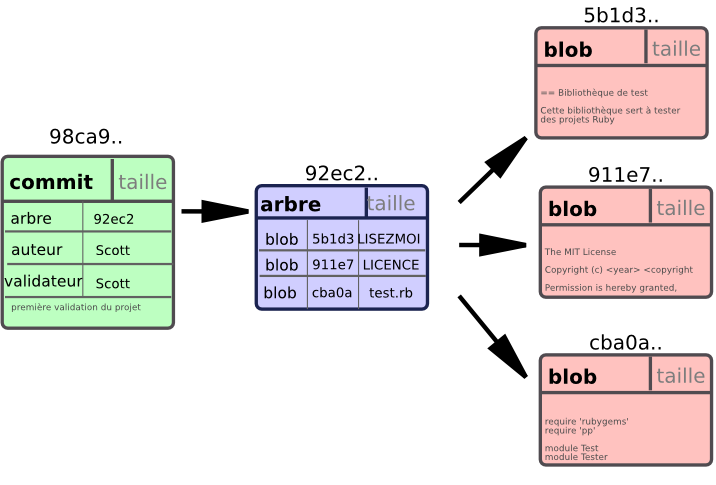
Pour visualiser ce concept, supposons un répertoire contenant trois fichiers, ces trois fichiers étant indexés puis validés. Indexer les fichiers signifie calculer la somme de contrôle pour chacun (la fonction de hachage SHA-1 mentionnée au chapitre 1), stocker cette version du fichier dans le dépôt Git (Git les nomme blobs) et ajouter la somme de contrôle à la zone d'index :
$ git add LISEZMOI test.rb LICENCE
$ git commit -m 'commit initial de mon projet'Lorsque vous créez le commit en lançant la commande git commit, Git calcule la somme de contrôle de chaque répertoire (ici, seulement pour le répertoire racine) et stocke ces objets arbres dans le dépôt Git. Git crée alors un objet commit qui contient les métadonnées et un pointeur vers l'arbre projet d'origine de manière à pouvoir recréer l'instantané si besoin.
Votre dépôt Git contient à présent cinq objets : un blob pour le contenu de chacun des trois fichiers, un arbre qui liste les contenus des répertoires et spécifie quels noms de fichier sont attachés à quels blobs et un objet commit avec le pointeur vers l'arbre d'origine et toutes les métadonnées attachées au commit. Conceptuellement, les données contenues dans votre dépôt git ressemblent à la Figure 3-1.
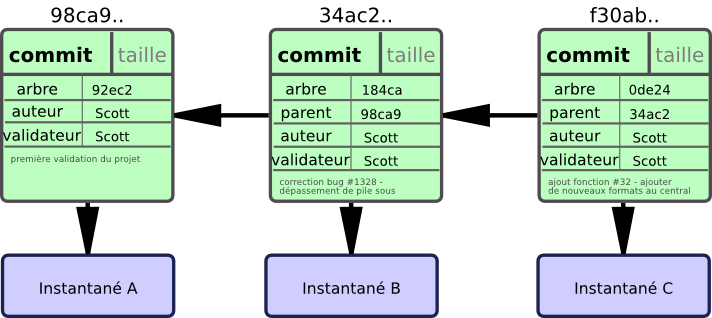
Si vous réalisez des modifications et validez à nouveau, le prochain commit stocke un pointeur vers le commit immédiatement précédent. Après deux autres validations, l'historique pourrait ressembler à la figure 3-2.
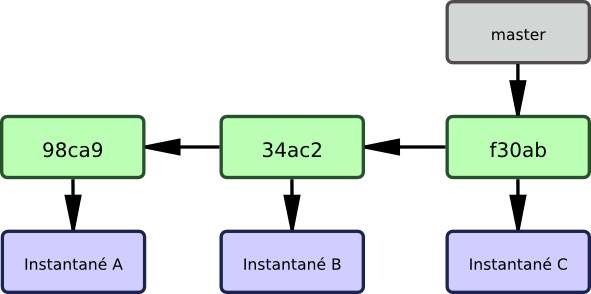
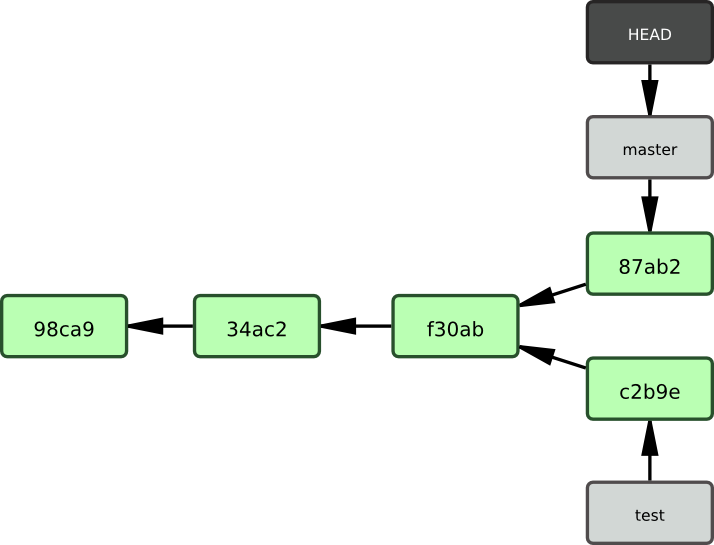
Une branche dans Git est tout simplement un pointeur mobile léger vers un de ces objets commit. La branche par défaut dans Git s'appelle master. Au fur et à mesure des validations, la branche master pointe vers le dernier des commits réalisés. À chaque validation, le pointeur de la branche master avance automatiquement.
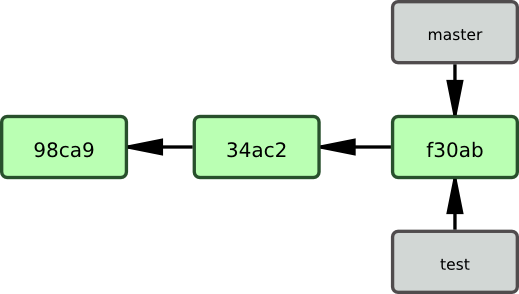
Que se passe-t-il si vous créez une nouvelle branche ? Et bien, cela crée un nouveau pointeur à déplacer. Supposons que vous créez une nouvelle branche nommée testing. Vous utilisez la commande git branch :
$ git branch testingCela crée un nouveau pointeur vers le commit actuel (cf. figure 3-4).
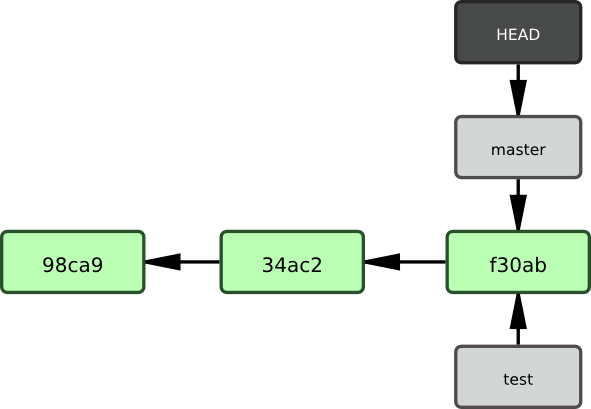
Comment Git connaît-il la branche sur laquelle vous vous trouvez ? Il conserve un pointeur spécial appelé HEAD. Remarquez que sous cette appellation se cache un concept très différent de celui utilisé dans les autres VCS tels que Subversion ou CVS. Dans Git, c'est un pointeur sur la branche locale où vous vous trouvez. Dans notre cas, vous vous trouvez toujours sur master. La commande git branch n'a fait que créer une nouvelle branche - elle n'a pas fait basculer la copie de travail vers cette branche (cf. figure 3-5).
Pour basculer vers une branche existante, il suffit de lancer la commande git checkout. Basculons vers la nouvelle branche testing :
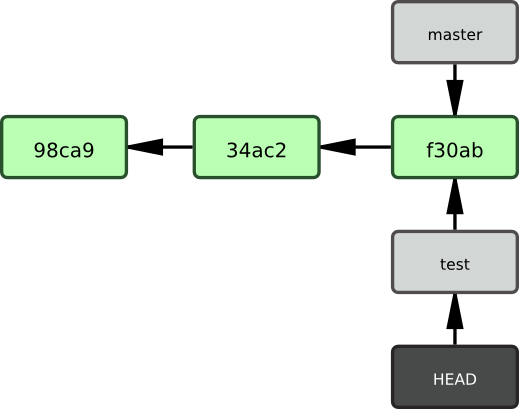
$ git checkout testingCela déplace HEAD pour le faire pointer vers la branche testing (voir figure 3-6)
Qu'est-ce que cela signifie ? Et bien, faisons une autre validation :
$ vim test.rb
$ git commit -a -m 'petite modification'La figure 3-7 illustre le résultat.
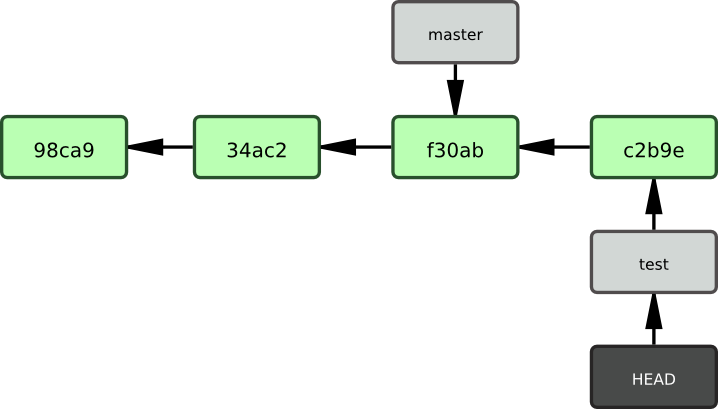
C'est intéressant parce qu'à présent, votre branche testing a avancé, tandis que la branche master pointe toujours sur le commit sur lequel vous étiez lorsque vous avez lancé git checkout pour basculer de branche. Retournons sur la branche master :
$ git checkout masterLa figure 3-8 montre le résultat.
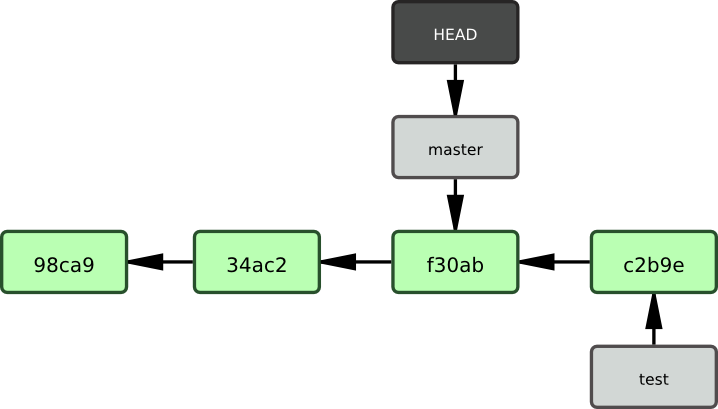
Cette commande a réalisé deux actions. Elle a remis le pointeur HEAD sur la branche master et elle a replacé les fichiers de la copie de travail dans l'état pointé par master. Cela signifie aussi que les modifications que vous réalisez à partir de maintenant divergeront de l'ancienne version du projet. Cette commande retire les modifications réalisées dans la branche testing pour vous permettre de repartir dans une autre direction de développement.
Réalisons quelques autres modifications et validons à nouveau :
$ vim test.rb
$ git commit -a -m 'autres modifications'Maintenant, l'historique du projet a divergé (voir figure 3-9). Vous avez créé une branche et basculé dessus, avez réalisé des modifications, puis avez rebasculé sur la branche principale et réalisé d'autres modifications. Ces deux modifications sont isolées dans des branches séparées. Vous pouvez basculer d'une branche à l'autre et les fusionner quand vous êtes prêt. Vous avez fait tout ceci avec de simples commandes branch et checkout.
Parce que dans Git, une branche n'est en fait qu'un simple fichier contenant les 40 caractères de la somme de contrôle SHA-1 du commit sur lequel elle pointe, les branches ne coûtent rien à créer et détruire. Créer une branche est aussi rapide qu'écrire un fichier de 41 caractères (40 caractères plus un retour chariot).
C'est une différence de taille avec la manière dont la plupart des VCS gèrent les branches, qui implique de copier tous les fichiers du projet dans un second répertoire. Cela peut durer plusieurs secondes ou même quelques minutes selon la taille du projet, alors que pour Git, le processus est toujours instantané. De plus, comme nous enregistrons les parents quand nous validons les modifications, la détermination de l'ancêtre commun pour la fusion est réalisée automatiquement et de manière très facile. Ces fonctionnalités encouragent naturellement les développeurs à créer et utiliser souvent des branches.
Voyons pourquoi vous devriez en faire autant.
III-B. Brancher et fusionner : les bases▲
Suivons un exemple simple de branche et fusion dans une utilisation que vous feriez dans le monde réel. Vous feriez les étapes suivantes :
- Travailler sur un site web ;
- Créer une branche pour une nouvelle Story sur laquelle vous souhaiteriez travailler ;
- Réaliser quelques tâches sur cette branche.
À cette étape, vous recevez un appel pour vous dire qu'un problème critique a été découvert et qu'il faut le régler au plus tôt. Vous feriez ce qui suit :
- Revenir à la branche de production ;
- Créer une branche et y développer le correctif ;
- Après un test, fusionner la branche de correctif et pousser le résultat à la production ;
- Rebasculer à la branche initiale et continuer le travail.
Le branchement de base▲
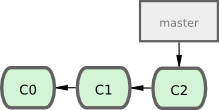
Premièrement, supposons que vous êtes à travailler sur votre projet et avez déjà quelques commits (voir figure 3-10).
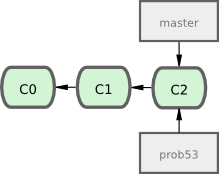
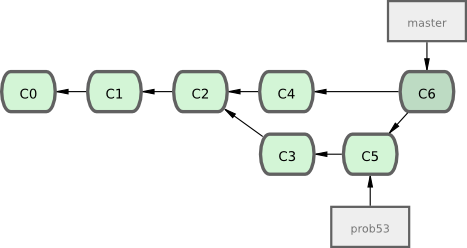
Vous avez décidé de travailler sur le problème numéroté #53 dans le suivi de faits techniques que votre entreprise utilise. Pour clarifier, Git n'est pas lié à un gestionnaire particulier de faits techniques. Mais comme le problème #53 est un problème ciblé sur lequel vous voulez travailler, vous allez créer une nouvelle branche dédiée à sa résolution. Pour créer une branche et y basculer tout de suite, vous pouvez lancer la commande git checkout avec l'option -b :
$ git checkout -b prob53
Switched to a new branch "prob53"C'est un raccourci pour :
$ git branch prob53
$ git checkout prob53La figure 3-11 illustre le résultat.
Vous travaillez sur votre site web et validez des modifications. Ce faisant, la branche prob53 avance, parce que vous l'avez extraite (c'est-à-dire que votre pointeur HEAD pointe dessus, voir figure 3-12) :
$ vim index.html
$ git commit -a -m 'ajout d'un pied de page [problème 53]'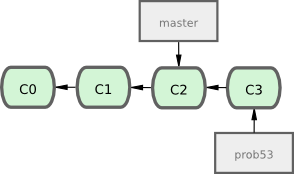
Maintenant vous recevez un appel qui vous apprend qu'il y a un problème sur le site web, un problème qu'il faut résoudre immédiatement. Avec Git, vous n'avez pas besoin de déployer les modifications déjà validées pour prob53 avec les correctifs du problème et vous n'avez pas non plus à suer pour éliminer ces modifications avant de pouvoir appliquer les correctifs du problème en production. Tout ce que vous avez à faire, c'est simplement rebasculer sur la branche master.
Cependant, avant de le faire, notez que si votre copie de travail ou votre zone de préparation contient des modifications non validées qui sont en conflit avec la branche que vous extrayez, Git ne vous laissera pas basculer de branche. Le mieux est d'avoir votre copie de travail dans un état propre au moment de basculer de branche. Il y a des moyens de contourner ceci (précisément par la planque et l'amendement de commit) dont nous parlerons plus loin. Pour l'instant, vous avez validé tous vos changements dans la branche prob53 et vous pouvez donc rebasculer vers la branche master :
$ git checkout master
Switched to branch "master"À présent, votre répertoire de copie de travail est exactement dans l'état précédent les modifications pour le problème #53 et vous pouvez vous consacrer à votre correctif. C'est un point important : Git réinitialise le répertoire de travail pour qu'il ressemble à l'instantané de la validation sur laquelle la branche que vous extrayez pointe. Il ajoute, retire et modifie les fichiers automatiquement pour assurer que la copie de travail soit identique à ce qu'elle était lors de votre dernière validation sur la branche.
Ensuite, vous avez un correctif à faire. Créons une branche de correctif sur laquelle travailler jusqu'à ce que ce soit terminé (voir figure 3-13) :
$ git checkout -b 'correctif'
Switched to a new branch "correctif"
$ vim index.html
$ git commit -a -m "correction d'une adresse mail incorrecte"
[correctif]: created 3a0874c: "correction d'une adresse mail incorrecte"
1 files changed, 0 insertions(+), 1 deletions(-)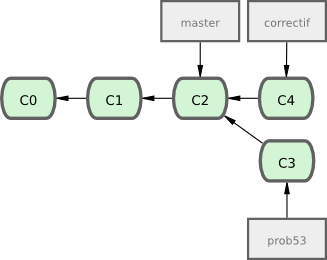
Vous pouvez lancer vos tests, vous assurer que la correction est efficace et la fusionner dans la branche master pour la déployer en production. Vous réalisez ceci au moyen de la commande git merge :
$ git checkout master
$ git merge correctif
Updating f42c576..3a0874c
Fast forward
LISEZMOI | 1 -
1 files changed, 0 insertions(+), 1 deletions(-)Vous noterez la mention “Fast forward? qui signifie avance rapide dans cette fusion. Comme le commit pointé par la branche que vous avez fusionnée était directement descendant du commit sur lequel vous vous trouvez, Git a avancé le pointeur en avant. Autrement dit, lorsque l'on cherche à fusionner un commit qui peut être joint en suivant l'historique depuis le commit d'origine, Git avance simplement le pointeur, car il n'y a pas de travaux divergeant à réellement fusionner - ceci s'appelle l'avance rapide.
Votre modification est maintenant dans l'instantané du commit pointé par la branche master et vous pouvez déployer votre modification (voir figure 3-14)
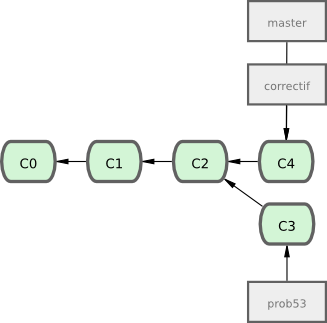
Après le déploiement de votre correction super-importante, vous voilà de nouveau prêt à travailler sur votre sujet précédent l'interruption. Cependant, vous allez avant tout effacer la branche correctif parce que vous n'en avez plus besoin et la branche master pointe au même endroit. Vous pouvez l'effacer avec l'option -d de la commande git branch :
$ git branch -d correctif
Deleted branch correctif (3a0874c).Maintenant, il est temps de basculer sur la branche “travaux en cours? sur le problème #53 et de continuer à travailler dessus (voir figure 3-15) :
$ git checkout prob53
Switched to branch "prob53"
$ vim index.html
$ git commit -a -m 'Nouveau pied de page terminé [problème 53]'
[prob53]: created ad82d7a: "Nouveau pied de page terminé [problème 53]"
1 files changed, 1 insertions(+), 0 deletions(-)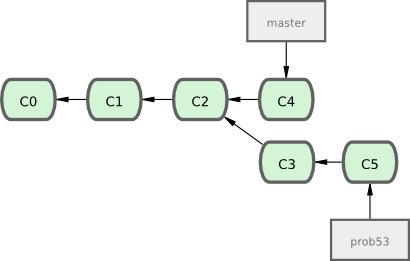
Il est utile de noter que le travail réalisé dans correctif n'est pas contenu dans les fichiers de la branche prob53. Si vous avez besoin de les y rapatrier, vous pouvez fusionner la branche master dans la branche prob53 en lançant la commande git merge master, ou vous pouvez retarder l'intégration de ces modifications jusqu'à ce que vous décidiez plus tard de rapatrier la branche prob53 dans master.
III-B-1. Les bases de la fusion▲
Supposons que vous ayez décidé que le travail sur le problème #53 est terminé et se trouve donc prêt à être fusionné dans la branche master. Pour ce faire, vous allez rapatrier votre branche prob53 de la même manière que vous l'avez fait plus tôt pour la branche correctif. Tout ce que vous avez à faire est d'extraire la branche dans laquelle vous souhaitez fusionner et lancer la commande git merge :
$ git checkout master
$ git merge prob53
Merge made by recursive.
README | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)Le comportement semble légèrement différent de celui observé pour la fusion précédente de correctif. Dans ce cas, l'historique de développement a divergé à un certain point. Comme le commit sur la branche sur laquelle vous vous trouvez n'est plus un ancêtre direct de la branche que vous cherchez à fusionner, Git doit travailler. Dans ce cas, Git réalise une simple fusion à trois sources, en utilisant les deux instantanés pointés par les sommets des branches et l'ancêtre commun des deux. La figure 3-16 illustre les trois instantanés que Git utilise pour réaliser la fusion dans ce cas.
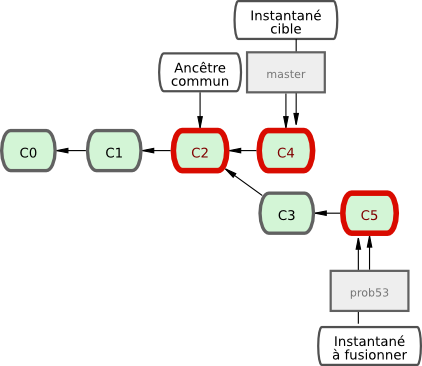
Au lieu de simplement d'avancer le pointeur de branche, Git crée un nouvel instantané qui résulte de la fusion à trois branches et crée automatiquement un nouveau commit qui pointe dessus (voir figure 3-17). On appelle ceci un commit de fusion, qui est spécial en ce qu'il comporte plus d'un parent.
Il est à noter que Git détermine par lui-même le meilleur ancêtre commun à utiliser comme base de fusion ; ce comportement est très différent de celui de CVS ou Subversion (antérieur à la version 1.5), où le développeur en charge de la fusion doit trouver par lui-même la meilleure base de fusion. Cela rend la fusion tellement plus facile dans Git que dans les autres systèmes.
À présent que votre travail a été fusionné, vous n'avez plus besoin de la branche prob53. Vous pouvez l'effacer et fermer manuellement le ticket dans votre outil de suivi de faits techniques :
$ git branch -d prob53III-B-2. Conflits de fusion▲
Quelques fois, le processus ci-dessus ne se passe pas sans accroc. Si vous avez modifié différemment la même partie du même fichier dans les deux branches que vous souhaitez fusionner, Git ne sera pas capable de réaliser proprement la fusion. Si votre résolution du problème #53 a modifié la même section de fichier que le correctif, vous obtiendrez un conflit de fusion qui ressemble à ceci :
$ git merge prob53
Auto-merging index.html
CONFLICT (content): Merge conflict in index.html
Automatic merge failed; fix conflicts and then commit the result.Git n'a pas automatiquement créé le commit du fusion. Il a arrêté le processus le temps que vous résolviez le conflit. Lancez git status pour voir à tout moment après l'apparition du conflit de fusion quels fichiers n'ont pas été fusionnés :
[master*]$ git status
index.html: needs merge
# On branch master
# Changed but not updated:
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working directory)
#
# unmerged: index.html
#Tout ce qui comporte des conflits de fusion et n'a pas été résolu est listé comme unmerged. Git ajoute des marques de conflit standard dans les fichiers qui comportent des conflits, pour que vous puissiez les ouvrir et résoudre les conflits manuellement. Votre fichier contient des sections qui ressemblent à ceci :
<<<<<<< HEAD:index.html
<div id="footer">contact : email.support@github.com</div>
=======
<div id="footer">
please contact us at support@github.com
</div>
>>>>>>> prob53:index.htmlCela signifie que la version dans HEAD (votre branche master, parce que c'est celle que vous aviez extraite quand vous avez lancé votre commande de fusion) est la partie supérieure de ce bloc (tout ce qui se trouve au-dessus de la ligne =======), tandis que la version de la branche prob53 se trouve en dessous. Pour résoudre le conflit, vous devez choisir une partie ou l'autre ou bien fusionner leurs contenus par vous-même. Par exemple, vous pourriez choisir de résoudre ce conflit en remplaçant tout le bloc par ceci :
<div id="footer">
please contact us at email.support@github.com
</div>Cette résolution comporte des parties de chaque section et les lignes <<<<<<<, ======= et >>>>>>> ont été complètement effacées. Après avoir résolu chacune de ces sections dans chaque fichier comportant un conflit, lancez git add sur chaque fichier pour le marquer comme résolu. Préparer le fichier en zone de préparation suffit à le marquer résolu pour Git. Si vous souhaitez utiliser un outil graphique pour résoudre ces problèmes, vous pouvez lancer git mergetool qui démarre l'outil graphique de fusion approprié et vous permet de naviguer dans les conflits :
$ git mergetool
merge tool candidates: kdiff3 tkdiff xxdiff meld gvimdiff opendiff emerge vimdiff
Merging the files: index.html
Normal merge conflict for 'index.html':
{local}: modified
{remote}: modified
Hit return to start merge resolution tool (opendiff):Si vous souhaitez utiliser un outil de fusion autre que celui par défaut (Git a choisi opendiff pour moi dans ce cas, car j'utilise la commande sous Mac), vous pouvez voir tous les outils supportés après l'indication “merge tool candidates?. Tapez le nom de l'outil que vous préféreriez utiliser. Au chapitre 7, nous expliquerons comment changer cette valeur par défaut dans votre environnement.
Après avoir quitté l'outil de fusion, Git vous demande si la fusion a été réussie. Si vous répondez par la positive à l'outil, il indexe le fichier pour le marquer comme résolu.
Vous pouvez lancer à nouveau la commande git status pour vérifier que tous les conflits ont été résolus :
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# modified: index.html
#Cela vous convient et vous avez vérifié que tout ce qui comportait un conflit a été indexé, vous pouvez taper la commande git commit pour finaliser le commit de fusion. Le message de validation ressemble d'habitude à ceci :
Merge branch 'prob53'
Conflicts:
index.html
#
# It looks like you may be committing a MERGE.
# If this is not correct, please remove the file
# .git/MERGE_HEAD
# and try again.
#Vous pouvez modifier ce message pour inclure les détails sur la résolution du conflit si vous pensez que cela peut être utile lors d'une revue ultérieure - pourquoi vous avez fait ceci si ce n'est pas clair.
III-C. Gestion de branches▲
Après avoir créé, fusionné et effacé des branches, regardons de plus près les outils de gestion de branche qui s'avèreront utiles lors d'une utilisation intensive des branches.
La commande git branch fait plus que créer et effacer des branches. Si vous la lancez sans argument, vous obtenez la liste des branches courantes :
$ git branch
prob53
* master
testingNotez le caractère * qui préfixe la branche master. Ce caractère indique la branche qui a été extraite. Ceci signifie que si vous validez des modifications, la branche master avancera avec votre travail. Pour visualiser les dernières validations sur chaque branche, vous pouvez lancer la commande git branch -v :
$ git branch -v
prob53 93b412c fix javascript issue
* master 7a98805 Merge branch 'prob53'
testing 782fd34 add scott to the author list in the readmesUne autre option permettant de voir l'état des branches permet de filtrer cette liste par les branches qui ont ou n'ont pas encore été fusionnées dans la branche courante. Les options --merged et --no-merge sont disponibles depuis la version 1.5.6 de Git. Pour voir quelles branches ont déjà été fusionnées dans votre branche actuelle, lancez git branch --merged :
$ git branch --merged
prob53
* masterComme vous avez déjà fusionné prob53 auparavant, vous la voyez dans votre liste. Les branches de cette liste qui ne comportent pas l'étoile en préfixe peuvent généralement être effacées sans risque au moyen de git branch -d ; vous avez déjà incorporé leurs modifications dans une autre branche et n'allez donc rien perdre.
Lancez git branch --no-merged pour visualiser les branches qui contiennent des travaux qui n'ont pas encore été fusionnés :
$ git branch --no-merged
testingCeci montre votre autre branche. Comme elle contient des modifications qui n'ont pas encore été fusionnées, un essai d'effacement par git branch -d se solde par un échec :
$ git branch -d testing
error: The branch 'testing' is not an ancestor of your current HEAD.
If you are sure you want to delete it, run 'git branch -D testing'.Si vous souhaitez réellement effacer cette branche et perdre ainsi le travail réalisé, vous pouvez forcer l'effacement avec l'option -D, comme l'indique justement le message.
III-D. Travailler avec les branches▲
Après avoir acquis les bases pour brancher et fusionner, que pouvons-nous ou devons-nous en faire ? Ce chapitre traite des différents styles de développement que cette gestion de branche légère permet de mettre en place, pour vous aider à décider d'en incorporer une dans votre cycle de développement.
III-D-1. Branches au long cours▲
Comme Git utilise une fusion à 3 branches, fusionner une branche dans une autre plusieurs fois sur une longue période est généralement facile. Cela signifie que vous pouvez travailler sur plusieurs branches ouvertes en permanence pendant plusieurs étapes de votre cycle de développement ; vous pouvez fusionner régulièrement certaines dans d'autres.
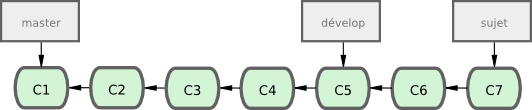
De nombreux développeurs utilisent Git avec une méthode qui utilise cette approche, telle que n'avoir que du code entièrement stable et testé dans la branche master, voire du code qui a été ou sera publié. Ils ont une autre branche en parallèle appelée develop qui, lorsqu'elle devient stable, peut être fusionnée dans master. Cette branche est utilisée pour tirer des branches spécifiques (branches avec une faible durée de vie, telles que notre branche prob53) quand elles sont prêtes, s'assurer qu'elles passent tous les tests et n'introduisent pas de bugs.
En réalité, nous parlons de pointeurs qui se déplacent le long des lignes des commits réalisés. Les branches stables sont plus en profondeur dans la ligne de l'historique des commits tandis que les branches des derniers développements sont plus en hauteur dans l'historique (voir figure 3-18).
C'est généralement plus simple d'y penser en terme de silos de tâches, où un ensemble de commits évolue vers un silo plus stable quand il a été complètement testé (voir figure 3-19).
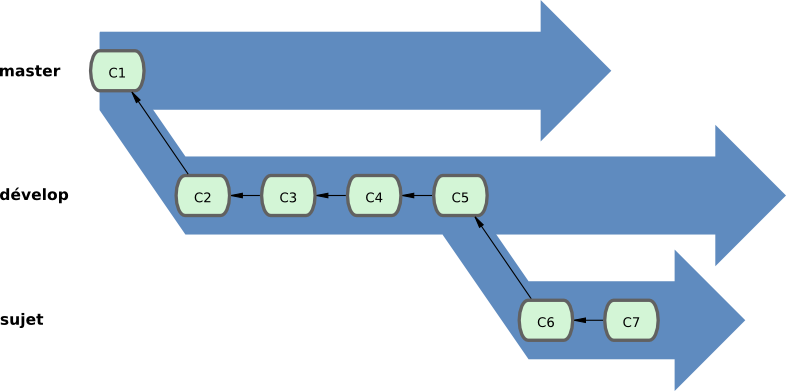
Vous pouvez reproduire ce schéma sur plusieurs niveaux de stabilité. Des projets plus gros ont aussi une branche proposed ou pu (proposed updates) qui permet d'intégrer des branches qui ne sont pas encore prêtes pour la prochaine version ou pour master. L'idée reste que les branches évoluent à différents niveaux de stabilité ; quand elles atteignent un niveau plus stable, elles peuvent être fusionnées dans la branche de stabilité supérieure. Une fois encore, les branches au long cours ne sont pas nécessaires, mais s'avèrent souvent utiles, spécialement dans le cadre de projets gros ou complexes.
III-D-2. Les branches de sujet▲
Les branches de sujet sont tout de même utiles quelle que soit la taille du projet. Une branche de sujet est une branche de courte durée de vie créée et utilisée pour une fonctionnalité ou une tâche particulière. C'est une manière d'opérer que vous n'avez vraisemblablement jamais utilisée avec un autre VCS parce qu'il est généralement trop lourd de créer et fusionner des branches. Mais dans Git, créer, développer, fusionner et effacer des branches plusieurs fois par jour est monnaie courante.
Vous l'avez remarqué dans la section précédent avec les branches prob53 et correctif que vous avez créées. Vous avez réalisé quelques validations sur elles et vous les avez effacées juste après les avoir fusionnées dans votre branche principale. Cette technique vous permet de basculer de contexte complètement et immédiatement. Il est beaucoup plus simple de réaliser des revues de code parce que votre travail est isolé dans des silos où toutes les modifications sont liées au sujet . Vous pouvez entreposer vos modifications ici pendant des minutes, des jours ou des mois, puis les fusionner quand elles sont prêtes, indépendamment de l'ordre dans lequel elles ont été créées ou de développées.
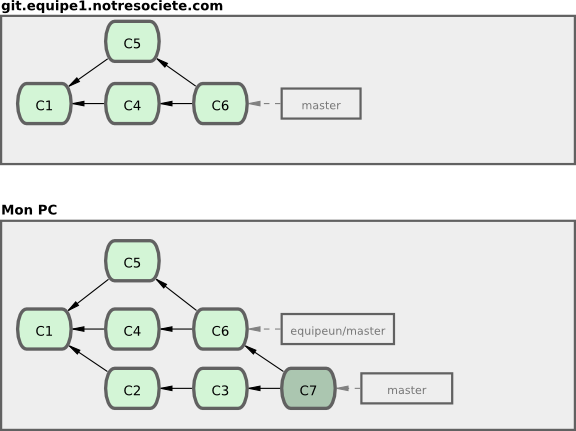
Supposons un exemple où pendant un travail (sur master), vous branchiez pour un problème (prob91), travaillez un peu dessus, vous branchiez une seconde branche pour essayer de trouver une autre manière de le résoudre (prob91v2), vous retourniez sur la branche master pour y travailler pendant un moment pour finalement brancher sur une dernière branche (ideeidiote) pour laquelle vous n'êtes pas sûr que ce soit une bonne idée. Votre historique de commit pourrait ressembler à la figure 3-20.
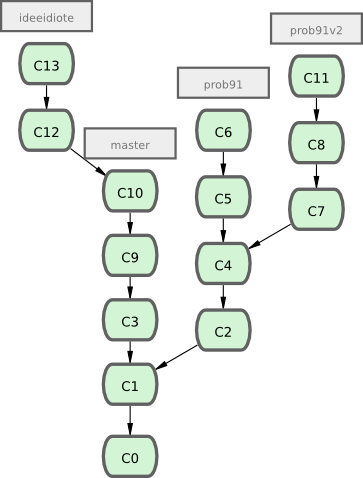
Maintenant, supposons que vous décidiez que vous préférez la seconde solution pour le problème (prob91v2) et que vous ayez montré la branche ideeidiote à vos collègues qui vous ont dit qu'elle était géniale. Vous pouvez jeter la branche prob91 originale (en effaçant les commits C5 et C6) et fusionner les deux autres. Votre historique ressemble à présent à la figure 3-21.
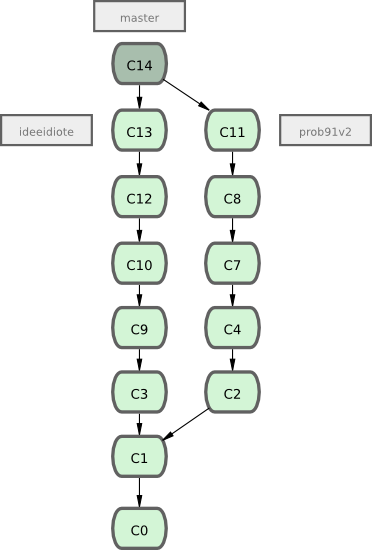
Souvenez-vous que lors de la réalisation de ces actions, toutes ces branches sont complètement locales. Lorsque vous branchez et fusionnez, tout est réalisé dans votre dépôt Git. Aucune communication avec un serveur n'a lieu.
III-E. Les branches distantes▲
Les branches distantes sont des références à l'état des branches sur votre dépôt distant. Ce sont des branches locales qu'on ne peut pas modifier ; elles sont modifiées automatiquement lors de communications réseau. Les branches distantes agissent comme des marques-pages pour vous aider à vous souvenir de l'état de votre dépôt distant lorsque vous vous y êtes connectés.
Elles prennent la forme de (distant)/(branche). Par exemple, si vous souhaitiez visualiser l'état de votre branche master sur le dépôt distant origin lors de votre dernière communication, il vous suffit de vérifier la branche origin/master. Si vous étiez en train de travailler avec un collègue et qu'il a mis à jour la branche prob53, vous pourriez avoir votre propre branche prob53 ; mais la branche sur le serveur pointerait sur le commit de origin/prob53.
Cela peut paraître déconcertant, alors éclaircissons les choses par un exemple. Supposons que vous avez un serveur Git sur le réseau à l'adresse git.notresociete.com. Si vous clonez à partir de ce serveur, Git le nomme automatiquement origin et en tire tout l'historique, crée un pointeur sur l'état actuel de la branche master et l'appelle localement origin/master ; vous ne pouvez pas la modifier. Git vous crée votre propre branche master qui démarre au même commit que la branche master d'origine, pour que vous puissiez commencer à travailler (voir figure 3-22).
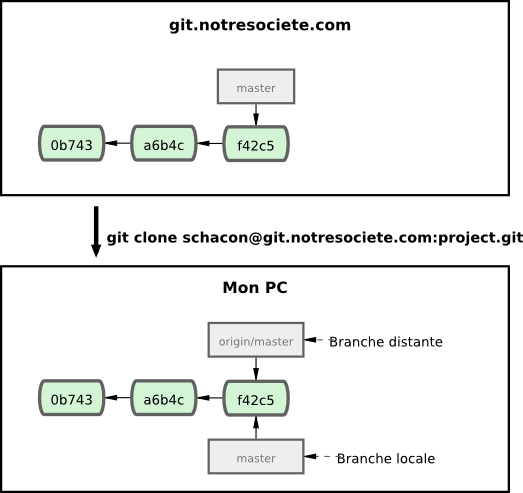
Si vous travaillez sur votre branche locale master et que dans le même temps, quelqu'un pousse vers git.notresociete.com et met à jour cette branche, alors vos deux historiques divergent. Tant que vous restez sans contact avec votre serveur distant, votre pointeur origin/master n'avance pas (voir figure 3-23).
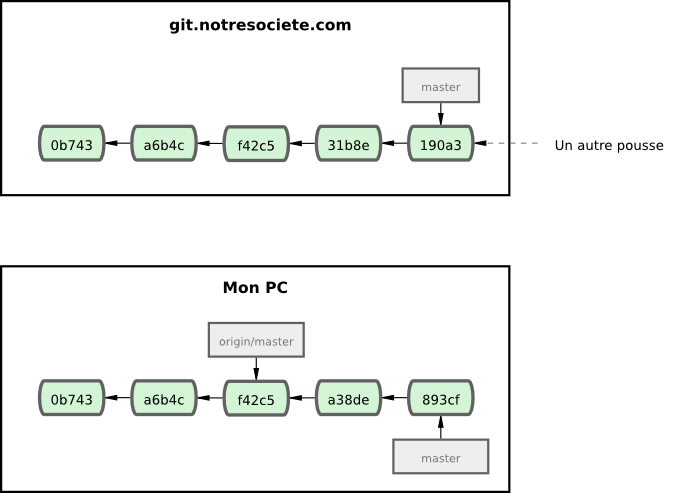
Lancez la commande git fetch origin pour synchroniser votre travail. Cette commande recherche le serveur hébergeant origin (dans notre cas, git.notresociete.com), en récupère toutes les nouvelles données et met à jour votre base de données locale en déplaçant votre pointeur origin/master à sa valeur nouvelle à jour avec le serveur distant (voir figure 3-24).
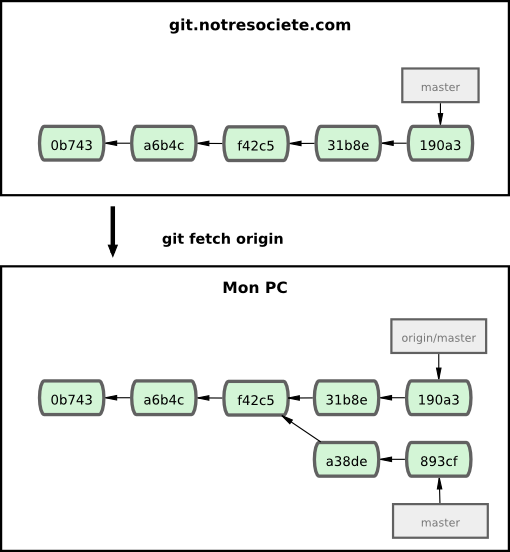
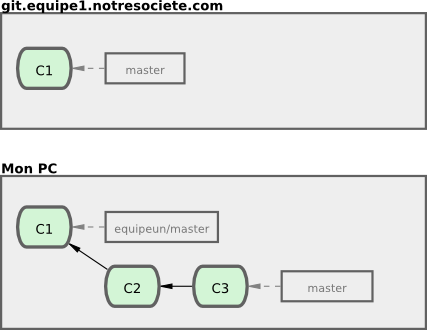
Pour démontrer l'usage de multiples serveurs distants et le fonctionnement avec des branches multiples, supposons que vous avez un autre serveur Git interne qui n'est utilisé pour le développement que par une équipe. Ce serveur se trouve sur git.equipe1.notresociete.com. Vous pouvez l'ajouter aux références distantes de votre projet actuel en lançant la commande git remote add comme nous l'avons décrit au chapitre 2. Nommez ce serveur distant equipeun qui sera le raccourci pour l'URL complète (voir figure 3-25).
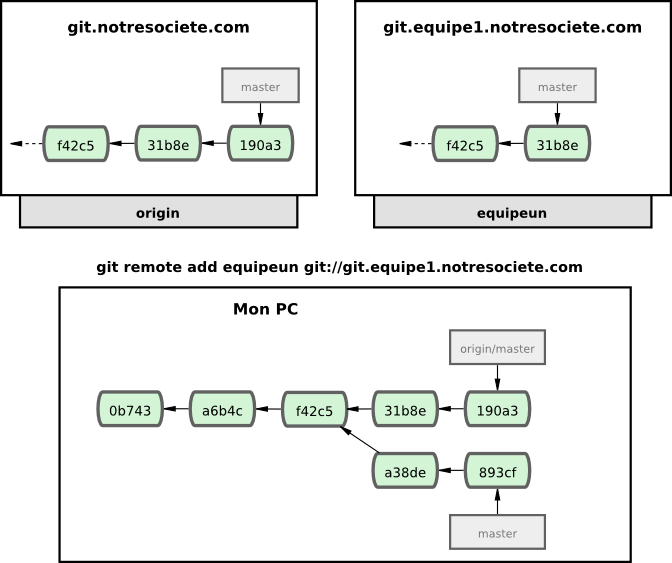
Maintenant, lancez git fetch equipeun pour récupérer l'ensemble des informations du serveur distant equipeun que vous ne possédez pas. Comme ce serveur contient déjà un sous-ensemble des données du serveur origin, Git ne récupère aucune donnée, mais positionne une branche distante appelée equipeun/master qui pointe sur le commit que equipeun a comme branche master (voir figure 3-26).
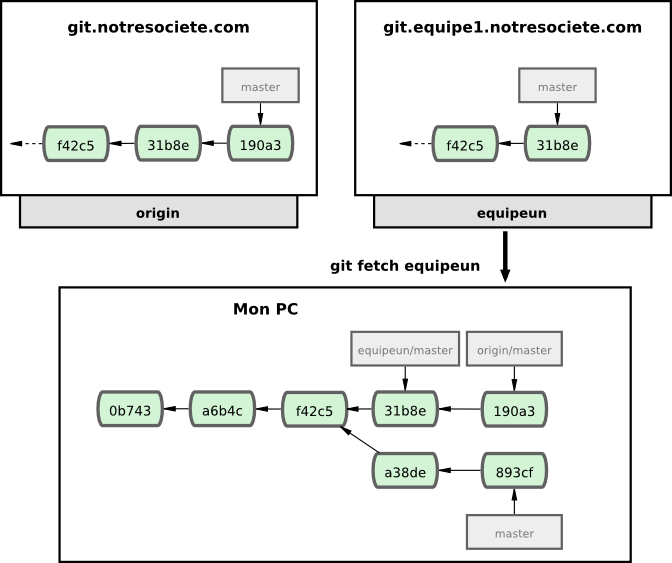
III-E-1. Pousser vers un serveur▲
Lorsque vous souhaitez partager une branche avec le reste du monde, vous devez la pousser sur le serveur distant sur lequel vous avez accès en écriture. Vos branches locales ne sont pas automatiquement synchronisées sur les serveurs distants - vous devez pousser explicitement les branches que vous souhaitez partager. De cette manière, vous pouvez utiliser des branches privées pour le travail que vous ne souhaitez pas partager et ne pousser que les branches sur lesquelles vous souhaitez collaborer.
Si vous possédez une branche nommée correctionserveur sur laquelle vous souhaitez travailler avec des tiers, vous pouvez la pousser de la même manière que vous avez poussé votre première branche. Lancez git push [serveur distant] [branche] :
$ git push origin correctionserveur
Counting objects: 20, done.
Compressing objects: 100% (14/14), done.
Writing objects: 100% (15/15), 1.74 KiB, done.
Total 15 (delta 5), reused 0 (delta 0)
To git@github.com:schacon/simplegit.git
* [new branch] correctionserveur -> correctionserveurC'est un raccourci. En fait, Git étend le nom de branche correctionserveur en refs/heads/correctionserveur:refs/heads/correctionserveur, ce qui signifie « Prendre ma branche locale correctionserveur et la pousser pour mettre à jour la branche distante correctionserveur ». Nous traiterons plus en détail la partie refs/heads/ au chapitre 9, mais vous pouvez généralement l'oublier. Vous pouvez aussi lancer git push origin correctionserveur:correctionserveur, qui réalise la même chose - ce qui signifie « Prendre ma branche correctionserveur et en faire la branche correctionserveur distante ». Vous pouvez utiliser ce format pour pousser une branche locale vers une branche distante nommée différemment. Si vous ne souhaitez pas l'appeler correctionserveur sur le serveur distant, vous pouvez lancer à la place git push origin correctionserveur:branchegeniale pour pousser votre branche locale correctionserveur sur la branche branchegeniale sur le projet distant.
La prochaine fois qu'un de vos collaborateurs récupère les données depuis le serveur, il récupérera une référence à l'état de la branche distante origin/correctionserveur :
$ git fetch origin
remote: Counting objects: 20, done.
remote: Compressing objects: 100% (14/14), done.
remote: Total 15 (delta 5), reused 0 (delta 0)
Unpacking objects: 100% (15/15), done.
From git@github.com:schacon/simplegit
* [new branch] correctionserveur -> origin/correctionserveurImportant : lorsque l'on récupère une nouvelle branche depuis un serveur distant, il n'y a pas de création automatique d'une copie locale éditable. En d'autres termes, il n'y a pas de branche correctionserveur, seulement un pointeur sur la branche origin/correctionserveur qui n'est pas modifiable.
Pour fusionner ce travail dans votre branche actuelle de travail, vous pouvez lancer git merge origin/correctionserveur. Si vous souhaitez créer votre propre branche correctionserveur pour pouvoir y travailler, vous pouvez la baser sur le pointeur distant :
$ git checkout -b correctionserveur origin/correctionserveur
Branch correctionserveur set up to track remote branch refs/remotes/origin/correctionserveur.
Switched to a new branch "correctionserveur"Cette commande vous fournit une branche locale modifiable basée sur l'état actuel de origin/correctionserveur.
III-E-2. Suivre les branches▲
L'extraction d'une branche locale à partir d'une branche distante crée automatiquement ce qu'on appelle une branche de suivi. Les branches de suivi sont des branches locales qui sont en relation directe avec une branche distante. Si vous vous trouvez sur une branche de suivi et que vous tapez git push, Git sélectionne automatiquement le serveur vers lequel pousser vos modifications. De même, git pull sur une de ces branches récupère toutes les références distantes et les fusionne automatiquement dans la branche distante correspondante.
Lorsque vous clonez un dépôt, il crée généralement automatiquement une branche master qui suit origin/master. C'est pourquoi les commandes git push et git pull fonctionnent directement sans plus de paramétrage. Vous pouvez néanmoins créer d'autres branches de suivi si vous le souhaitez, qui ne suivront pas origin ni la branche master. Un cas d'utilisation simple est l'exemple précédent, en lançant git checkout -b [branche] [nomdistant]/[branche]. Si vous avez Git version 1.6.2 ou plus, vous pouvez aussi utiliser l'option courte --track :
$ git checkout --track origin/correctionserveur
Branch correctionserveur set up to track remote branch refs/remotes/origin/correctionserveur.
Switched to a new branch "correctionserveur"Pour créer une branche locale avec un nom différent de celui de la branche distante, vous pouvez simplement utiliser la première version avec un nom de branch locale différent :
$ git checkout -b sf origin/correctionserveur
Branch sf set up to track remote branch refs/remotes/origin/correctionserveur.
Switched to a new branch "sf"À présent, votre branche locale sf poussera vers et tirera automatiquement depuis origin/correctionserveur.
III-E-3. Effacer des branches distantes▲
Supposons que vous en avez terminé avec une branche distante. Vous et vos collaborateurs avez terminé une fonctionnalité et l'avez fusionnée dans la branche master du serveur distant (ou la branche correspondant à votre code stable). Vous pouvez effacer une branche distante en utilisant la syntaxe plutôt obtuse git push [nomdistant] :[branch]. Si vous souhaitez effacer votre branche correctionserveur du serveur, vous pouvez lancer ceci :
$ git push origin :correctionserveur
To git@github.com:schacon/simplegit.git
- [deleted] correctionserveurBoum ! Plus de branche sur le serveur. Vous souhaiterez sûrement corner cette page parce que vous aurez besoin de cette commande et il y a de fortes chances que vous en oubliez la syntaxe. Un moyen mnémotechnique est de l'associer à la syntaxe de la commande git push [nomdistant] [branchelocale]:[branchedistante] que nous avons utilisé précédemment. Si vous éliminez la partie [branchelocale], cela signifie « ne rien prendre de mon côté et en faire [branchedistante] ».
III-F. Rebaser▲
Dans Git, il y a deux façons d'intégrer les modifications d'une branche dans une autre : en fusionnant merge et en rebasant rebase. Dans ce chapitre, vous apprendrez la signification de rebaser, comment le faire, pourquoi c'est un outil plutôt ébouriffant et dans quels cas il est déconseillé de l'utiliser.
III-F-1. Les bases▲
Si vous revenez à un exemple précédent du chapitre sur la fusion (voir la figure 3-27), vous remarquerez que votre travail a divergé et que vous avez ajouté de commits sur deux branches différentes.
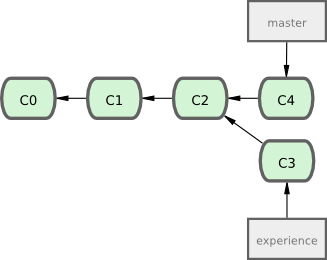
Comme nous l'avons déjà expliqué, le moyen le plus simple pour intégrer ensemble ces branches est la fusion via la commande merge. Cette commande réalise une fusion à trois branches entre les deux derniers instantanés de chaque branche (C3 et C4) et l'ancêtre commun le plus récent (C2), créant un nouvel instantané (et un commit), comme montré par la figure 3-28.
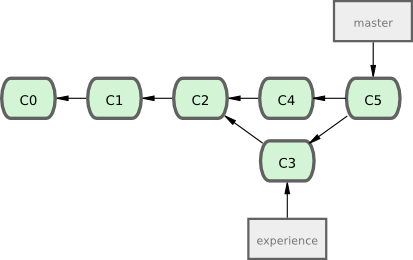
Cependant, il existe un autre moyen : vous pouvez prendre le patch de la modification introduite en C3 et le réappliquer sur C4. Dans Git, cette action est appelée rebaser. Avec la commande rebase, vous prenez toutes les modifications qui ont été validées sur une branche et vous les rejouez sur une autre.
Dans cet exemple, vous lanceriez les commandes suivantes :
$ git checkout experience
$ git rebase master
First, rewinding head to replay your work on top of it...
Applying: added staged commandCela fonctionne en cherchant l'ancêtre commun le plus récent des deux branches (celle sur laquelle vous vous trouvez et celle sur laquelle vous rebasez), en récupérant toutes les différences introduites entre chaque validation de la branche sur laquelle vous êtes, en les sauvant dans des fichiers temporaires, en basculant sur la branche destination et en réappliquant chaque modification dans le même ordre. La figure 3-29 illustre ce processus.
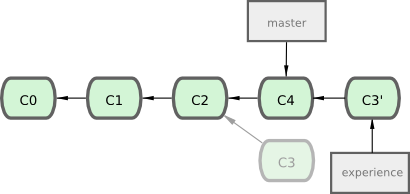
À ce moment, vous pouvez retourner sur la branche master et réaliser une fusion en avance rapide (voir figure 3-30).
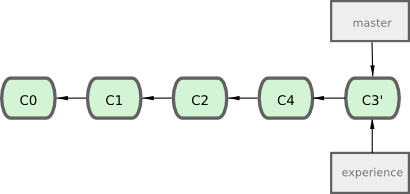
À présent, l'instantané pointé par C3' est exactement le même que celui pointé par C5 dans l'exemple de fusion. Il n'y a pas de différence entre les résultats des deux types d'intégration, mais rebaser rend l'historique plus clair. Si vous examinez le journal de la branche rebasée, elle est devenue linéaire : toutes les modifications apparaissent en série même si elles ont eu lieu en parallèle.
Vous aurez souvent à rebaser pour vous assurer que les patchs que vous envoyez s'appliquent correctement sur une branche distante - par exemple, sur un projet où vous souhaitez contribuer, mais que vous ne maintenez pas. Dans ce cas, vous réaliseriez votre travail dans une branche puis vous rebaseriez votre travail sur origin/master quand vous êtes prêt à soumettre vos patches au projet principal. De cette manière, le mainteneur n'a pas à réaliser de travail d'intégration - juste une avance rapide ou simplement une application propre.
Il faut noter que l'instantané pointé par le commit final, qu'il soit le dernier des commits d'une opération de rebase ou le commit final issu d'une fusion, sont en fait le même instantané - c'est juste que l'historique est différent. Rebaser rejoue les modifications d'une ligne de commits sur une autre dans l'ordre d'apparition, alors que la fusion joint et fusionne les deux têtes.
III-F-2. Rebasages plus intéressants▲
Vous pouvez aussi faire rejouer votre rebasage sur autre chose qu'une branche. Prenez l'historique de la figure 3-31 par exemple. Vous avez créé une branche pour un sujet spécifique (server) pour ajouter des fonctionnalités côté serveur à votre projet et avez réalisé un commit. Ensuite, vous avez créé une branche pour ajouter des modifications côté client (client) et avez validé plusieurs fois. Finalement, vous avez rebasculé sur la branche server et avez réalisé quelques commits supplémentaires.
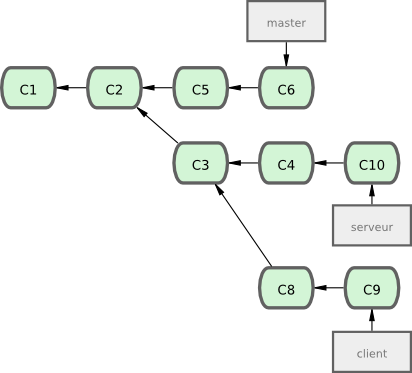
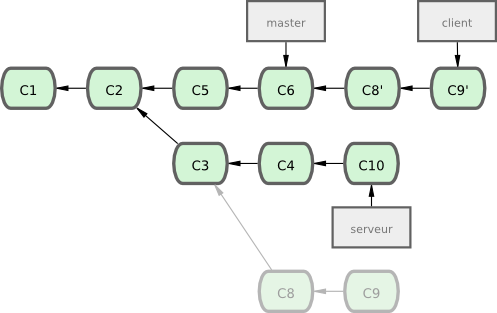
Supposons que vous décidez que vous souhaitez fusionner vos modifications pour le côté client dans votre ligne principale pour une publication, mais vous souhaitez retenir les modifications pour la partie serveur jusqu'à ce qu'elles soient un peu plus testées. Vous pouvez récupérer les modifications pour le côté client qui ne sont pas sur le serveur (C8 et C9) et les rejouer sur la branche master en utilisant l'option --onto de git rebase :
$ git rebase --onto master server clientCela signifie en essence « Extrait la branche client, détermine les patchs depuis l'ancêtre commun des branches client et server puis rejoue-les sur master ». C'est assez complexe, mais le résultat visible sur la figure 3-32 est assez impressionnant.
Maintenant, vous pouvez faire une avance rapide sur votre branche master (voir figure 3-33) :
$ git checkout master
$ git merge client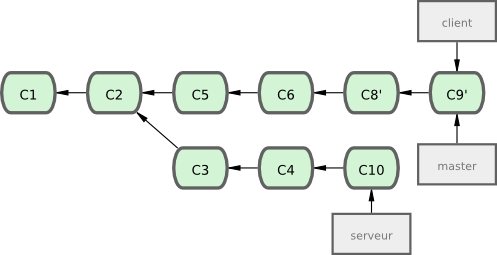
Supposons que vous décidiez de tirer de votre branche server aussi. Vous pouvez rebaser la branche server sur la branche master sans avoir à l'extraire avant en utilisant git rebase [branchedebase] [branchedesujet] - qui extrait la branche de sujet (dans notre cas, server) pour vous et la rejoue sur la branche de base (master) :
$ git rebase master serverCette commande rejoue les modifications de server sur le sommet de la branche master, comme indiqué dans la figure 3-34.
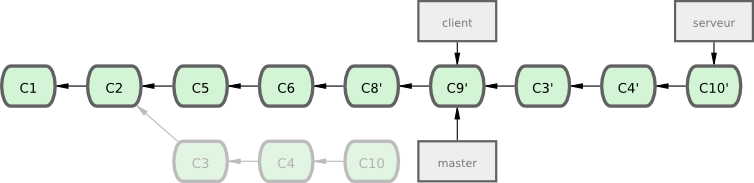
Ensuite, vous pouvez faire une avance rapide sur la branche de base (master) :
$ git checkout master
$ git merge serverVous pouvez effacer les branches client et server une fois que tout le travail est intégré et que vous n'en avez plus besoin, éliminant tout l'historique de ce processus, comme visible sur la figure 3-35 :
$ git branch -d client
$ git branch -d server
III-F-3. Les dangers de rebaser▲
Ah… mais les joies de rebaser ne viennent pas sans leurs contreparties, qui peuvent être résumées en une ligne :
Ne rebasez jamais des commits qui ont déjà été poussés sur un dépôt public.
Si vous suivez ce conseil, tout ira bien. Sinon, de nombreuses personnes vont vous haïr et vous serez méprisé par vos amis et votre famille.
Quand vous rebasez des données, vous abandonnez les commits existants et vous en créez de nouveaux qui sont similaires, mais différents. Si vous poussez des commits quelque part et que d'autre les tirent et se basent dessus pour travailler et qu'après coup, vous réécrivez ces commits à l'aide de git rebase et les poussez à nouveau, vos collaborateurs devront re-fusionner leur travail et les choses peuvent rapidement devenir très désordonnées quand vous essaierez de tirer leur travail dans votre dépôt.
Examinons un exemple expliquant comment rebaser un travail déjà publié sur un dépôt public peut générer des gros problèmes. Supposons que vous clonez un dépôt depuis un serveur central et réalisez quelques travaux dessus. Votre historique de commits ressemble à la figure 3-36.
À présent, une autre personne travaille et inclut une fusion, puis elle pousse ce travail sur le serveur central. Vous le récupérez et vous fusionnez la nouvelle branche distante dans votre copie, ce qui donne l'historique de la figure 3-37.
Ensuite, la personne qui a poussé le travail que vous venez de fusionner décide de faire marche arrière et de rebaser son travail. Elle lance un git push --force pour forcer l'écrasement de l'historique sur le serveur. Vous récupérez alors les données du serveur, qui vous amènent les nouveaux commits.
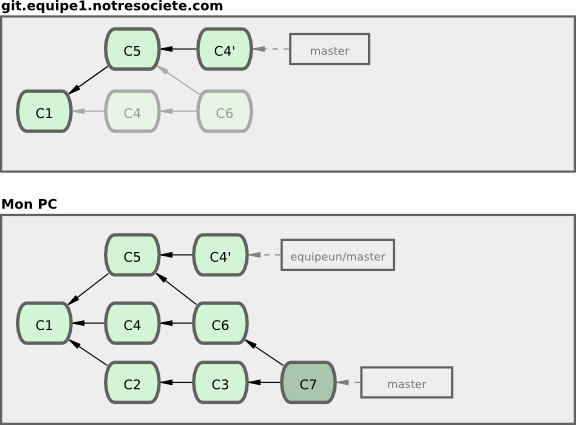
À ce moment, vous devez fusionner son travail une nouvelle fois, même si vous l'avez déjà fait. Rebaser change les empreintes SHA-1 de ces commits, ce qui les rend nouveaux aux yeux de Git, alors qu'en fait, vous avez déjà le travail de C4 dans votre historique (voir figure 3-39).
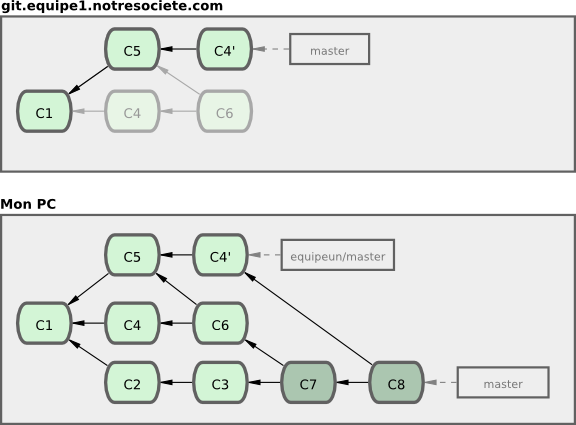
Vous devez fusionner ce travail pour pouvoir continuer à suivre ce développeur dans le futur. Après fusion, votre historique contient à la fois les commits C4 et C4', qui ont des empreintes SHA-1 différentes, mais introduisent les mêmes modifications et ont les mêmes messages de validation. Si vous lancez git log lorsque votre historique ressemble à ceci, vous verrez deux commits qui ont la même date d'auteur et les mêmes messages, ce qui est déroutant. De plus, si vous poussez cet historique sur le serveur, vous réintroduirez tous ces commits rebasés sur le serveur central, ce qui va encore plus dérouter les autres développeurs.
Si vous considérez le fait de rebaser comme un moyen de nettoyer et réarranger des commits avant de les pousser et si vous vous en tenez à ne rebaser que des commits qui n'ont jamais été publiés, tout ira bien. Si vous tentez de rebaser des commits déjà publiés sur lesquels les gens ont déjà basé leur travail, vous allez au-devant de gros problèmes énervants.
III-G. Résumé▲
Nous avons traité les bases des branches et de fusions dans Git. Vous devriez être à l'aise pour la création et le basculement sur de nouvelles branches, le basculement entre branches et la fusion de branches locales. Vous devriez aussi être capable de partager vos branches en les poussant sur un serveur partagé, travailler avec d'autres personnes sur des branches partagées et rebaser vos branches avant de les partager.
