



VI. Utilitaires Git▲
A présent, vous avez appris les commandes et modes de fonctionnements usuels requis pour gérer et maintenir un dépôt Git pour la gestion de votre code source. Vous avez déroulé les routines de suivi (tracking) et de consignation (committing) de fichiers, vous avez exploité la puissance de la zone d'attente (staging area), de la création et de la fusion de branches locales de travail.
Maintenant, vous allez explorer un certain nombre de fonctionnalités particulièrement efficaces, fonctionnalités que vous n'utiliserez que rarement mais dont vous pourriez avoir l'usage à un moment ou à un autre.
VI-A. Sélection des versions▲
Git vous permet d'adresser certains commits ou un ensemble de commits de différentes façons. Si elles ne sont pas toutes évidentes il est bon de les connaître.
VI-A-1. Révisions ponctuelles▲
Naturellement, vous pouvez référencer un commit par la signature SHA-1, mais il existe des méthodes plus confortables pour le genre humain. Cette section présente les méthodes pour référencer un commit simple.
VI-A-2. Empreinte SHA courte▲
Git est capable de deviner de quel commit vous parlez si vous ne fournissez que quelques caractères au début de la signature, tant que votre SHA-1 partiel comporte au moins 4 caractères et ne génère pas de collision. Dans ces conditions, un seul objet correspondra à ce SHA-1.
Par exemple, pour afficher un commit précis, supposons que vous exécutiez git log et que vous identifiez le commit où vous avez introduit une fonctionnalité précise.
$ git log
commit 734713bc047d87bf7eac9674765ae793478c50d3
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Jan 2 18:32:33 2009 -0800
fixed refs handling, added gc auto, updated tests
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Merge: 1c002dd... 35cfb2b...
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'
commit 1c002dd4b536e7479fe34593e72e6c6c1819e53b
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 14:58:32 2008 -0800
added some blame and merge stuffPour cet exemple, choisissons 1c002dd.... Si vous affichez le contenu de ce commit via git show, les commandes suivantes sont équivalentes (en partant du principe que les SHA-1 courts ne sont pas ambigüs).
$ git show 1c002dd4b536e7479fe34593e72e6c6c1819e53b
$ git show 1c002dd4b536e7479f
$ git show 1c002dGit peut déterminer un SHA tout à la fois le plus court possible et non ambigü. Ajoutez l'option --abbrev-commit à la commande git log et le résultat affiché utilisera des valeurs plus courtes mais uniques; par défaut git retiendra 7 caractères et augmentera au besoin :
$ git log --abbrev-commit --pretty=oneline
ca82a6d changed the version number
085bb3b removed unnecessary test code
a11bef0 first commitEn règle générale, entre 8 et 10 caractères sont largement suffisant pour assurer l'unicité dans un projet. Un des plus gros projets utilisant Git, le kernel Linux, nécessite de plus en plus fréquemment 12 caractères sur les 40 possibles pour assurer l'unicité.
VI-A-3. QUELQUES MOTS SUR SHA-1▲
Beaucoup de gens se soucient qu'à un moment donné ils auront, par des circonstances hasardeuses, deux objets dans leur référentiel de hachage de même empreinte SHA-1. Qu'en est-il réellement ?
S'il vous arrivait de consigner (commit) un objet qui se hache de la même empreinte SHA-1 d'un objet existant dans votre référentiel, Git verrez l'objet existant déjà dans votre base de données et Git présumera qu'il était déjà enregistré. Si vous essayez de récupérer l'objet de nouveau à un moment donné, vous aurez toujours les données du premier objet.
Quoi qu'il en soit, vous devriez être conscient à quel point ce scénario est ridiculement improbable. Une empreinte SHA-1 porte sur 20 octets soit 160bits. Le nombre d'objet aléatoires à hasher requis pour assurer une probabilité de collision de 50% vaut environ 2^80 (la formule pour calculer la probabilité de collision est p = (n(n-1)/2) * (1/2^160)). 2^80 vaut 1.2 x 10^24 soit 1 million de milliards de milliards. Cela représente 1200 fois le nombre de grains de sable sur terre.
Voici un exemple pour vous donner une idée de ce qui pourrait provoquer une collision du SHA-1. Si tous les 6,5 milliards d'humains sur Terre programmait et que chaque seconde, chacun produisait du code équivalent à l'historique entier du noyaux Linux (1 million d'objets Git) et le poussait sur un énorme dépôt Git, cela prendrait 5 ans pour que ce dépôt contienne assez d'objets pour avoir une probabilité de 50% qu'une seule collision SHA-1 existe. Il y a une probabilité plus grande que tous les membres de votre équipe de programmation serait attaqués et tués par des loups dans des incidents sans relation la même nuit.
VI-A-4. Références de branches▲
La méthode la plus commune pour désigner un commit est une branche y pointant. Dès lors, vous pouvez utiliser le nom de la branche dans toute commande utilisant un objet de type commit ou un SHA-1. Par exemple, si vous souhaitez afficher le dernier commit d'une branche, les commandes suivantes sont équivalentes, en supposant que la branche sujet1 pointe sur ca82a6d :
$ git show ca82a6dff817ec66f44342007202690a93763949
$ git show sujet1Pour connaître l'empreinte SHA sur lequel pointe une branche, ou pour savoir parmi tous les exemples précédents ce que cela donne en terme de SHA, vous pouvez utiliser la commande de plomberie nommée rev-parse. Se référer au chapitre 9 pour plus d'informations sur les commandes de plomberie; en résumé, rev-parse est là pour les opérations de bas niveau et n'est pas conçue pour être utilisée au jour le jour. Quoi qu'il en soit, cela peut se révéler utile pour comprendre ce qui se passe. Je vous invite à tester rev-parse sur votre propre branche.
$ git rev-parse sujet1
ca82a6dff817ec66f44342007202690a93763949VI-A-5. Raccourcis RefLog▲
Git maintient en arrière-plan un historique des références où sont passées HEAD et vos branches sur les dernieres mois - ceci s'appelle le reflog.
Vous pouvez le consulter avec la commande git reflog :
$ git reflog
734713b... HEAD@{0}: commit: fixed refs handling, added gc auto, updated
d921970... HEAD@{1}: merge phedders/rdocs: Merge made by recursive.
1c002dd... HEAD@{2}: commit: added some blame and merge stuff
1c36188... HEAD@{3}: rebase -i (squash): updating HEAD
95df984... HEAD@{4}: commit: # This is a combination of two commits.
1c36188... HEAD@{5}: rebase -i (squash): updating HEAD
7e05da5... HEAD@{6}: rebase -i (pick): updating HEADÀ chaque fois que l'extrémité de votre branche est modifiée, Git enregistre cette information pour vous dans son historique temporaire. Vous pouvez référencer d'anciens commits avec cette donnée. Si vous souhaitez consulter le n-ième antécédent de votre HEAD, vous pouvez utiliser la référence @{n} du reflog, 5 dans cet exemple :
$ git show HEAD@{5}Vous pouvez également remonter le temps et savoir où en était une branche à un moment donné. Par exemple, pour savoir où en était la branche master hier (yesterday en anglais), tapez :
$ git show master@{yesterday}Cette technique fonctionne uniquement si l'information est encore présente dans le reflog, vous ne pourrez donc pas consulter les commits trop anciens.
Pour consulter le reflog au format git log, exécutez: git log -g :
$ git log -g master
commit 734713bc047d87bf7eac9674765ae793478c50d3
Reflog: master@{0} (Scott Chacon <schacon@gmail.com>)
Reflog message: commit: fixed refs handling, added gc auto, updated
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Jan 2 18:32:33 2009 -0800
fixed refs handling, added gc auto, updated tests
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Reflog: master@{1} (Scott Chacon <schacon@gmail.com>)
Reflog message: merge phedders/rdocs: Merge made by recursive.
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'Veuillez noter que le reflog ne stocke que des informations locales, c'est un historique de ce que vous avez fait dans votre dépôt. Les références ne sont pas copiées dans un autre dépôt; et juste après le clone d'un dépôt, votre reflog sera vide, puisque qu'aucune activité ne s'y sera produite. Exécuter git show HEAD@{2.months.ago} ne fonctionnera que si vous avez dupliqué ce projet depuis au moins 2 mois - si vous l'avez dupliqué il y a 5 minutes, vous n'obtiendrez rien.
VI-A-6. Références passées▲
Une solution fréquente de référencer un commit est d'utiliser son ancêtre. Si vous suffixez une référence par ^, Git la résoudra comme étant le parent de cette référence. Supposons que vous consultiez votre historique :
$ git log --pretty=format:'%h %s' --graph
* 734713b fix sur la gestion des refs, ajout gc auto, mise à jour des tests
* d921970 Merge commit 'phedders/rdocs'
|\
| * 35cfb2b modifs minor rdoc
* | 1c002dd ajout blame and merge
|/
* 1c36188 ignore *.gem
* 9b29157 ajout open3_detach à la liste des fichiers gemspcecAlors, vous pouvez consulter le commit précédent en spécifiant HEAD^, ce qui signifie “le parent de HEAD :
$ git show HEAD^
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Merge: 1c002dd... 35cfb2b...
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'Vous pouvez également spécifier un nombre après ^ - par exemple, d921970^2 signifie “le second parent de d921970.. Cette syntaxe ne sert que pour les commits de fusion, qui ont plus d'un parent. Le premier parent est la branche où vous avez fusionné, et le second est le commit de la branche que vous avez fusionnée :
$ git show d921970^
commit 1c002dd4b536e7479fe34593e72e6c6c1819e53b
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 14:58:32 2008 -0800
ajout blame and merge
$ git show d921970^2
commit 35cfb2b795a55793d7cc56a6cc2060b4bb732548
Author: Paul Hedderly <paul+git@mjr.org>
Date: Wed Dec 10 22:22:03 2008 +0000
modifs minor rdocUne autre solution courante pour spécifier une référence est le ~. Il fait également référence au premier parent, donc HEAD~ et HEAD^ sont équivalents. La différence se fait sentir si vous spécifiez un nombre. HEAD~2 signifie “le premier parent du premier parent, ou bien “le grand-parent” ça remonte les premiers parents autant de fois que demandé. Par exemple, dans l'historique précédemment présenté, HEAD~3 serait :
$ git show HEAD~3
commit 1c3618887afb5fbcbea25b7c013f4e2114448b8d
Author: Tom Preston-Werner <tom@mojombo.com>
Date: Fri Nov 7 13:47:59 2008 -0500
ignore *.gemCela aura bien pu être écrit HEAD^^^, qui là encore est le premier parent du premier parent du premier parent :
$ git show HEAD^^^
commit 1c3618887afb5fbcbea25b7c013f4e2114448b8d
Author: Tom Preston-Werner <tom@mojombo.com>
Date: Fri Nov 7 13:47:59 2008 -0500
ignore *.gemVous pouvez également combiner ces syntaxes - vous pouvez obtenir le second parent de la référence précédente (en supposant que c'était un commit de fusion) en utilisant HEAD~3^2, etc.
VI-A-7. Plages de commits▲
A présent que vous pouvez spécifier des commits individuels, voyons comme spécifier une place de commits. Ceci est particulièrement pratique pour la gestion des branches - si vous avez beaucoup de branches, vous pouvez utiliser les plages pour adresser des problèmes tels que “Quelle activité sur cette branche n'ai-je pas encore fusionné sur ma branche principale ?.
VI-A-7-a. Double point▲
La plus fréquente spécification de plage de commit est la syntaxe double-point. En gros, cela demande à Git de résoudre la plage des commits qui sont accessible depuis un commit mais ne le sont pas depuis un autre. Par exemple, disons que votre historique ressemble à celui de la Figure 6-1.
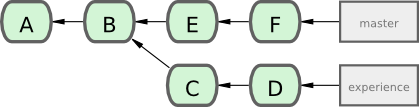
Si vous voulez savoir ce que n'a pas encore été fusionné sur votre branche master depuis votre branche experiment, vous pouvez demandez à Git de vous montrer un listing des commits avec master..experiment - ce qui signifie “tous les commits accessibles par experiment qui ne le sont pas par master.. Dans un souci de brièveté et de clarté de ces exemples, je vais utiliser les lettres des commits issus du diagramme à la place du vrai listing dans l'ordre où ils auraient dû être affichés :
$ git log master..experiment
D
CD'un autre côté, si vous souhaitez voir l'opposé - tous les commits dans master mais pas encore dans experiment - vous pouvez inverser les noms de branches, experiment..master vous montre tout ce que master accède mais qu'experiment ne voit pas :
$ git log experiment..master
F
EC'est pratique si vous souhaitez maintenir experiment à jour et anticiper les fusions. Une autre cas d'utilisation fréquent et de voir ce que vous vous appréter à pousser sur une branche distante :
$ git log origin/master..HEADCette commande vous affiche tous les commits de votre branche courante qui ne sont pas sur la branche master du dépôt distant origin. Si vous exécutez git push et que votre branche courante suit origin/master, les commits listés par git log origin/master..HEAD sont les commits qui seront transférés sur le serveur. Vous pouvez également laisser tomber une borne de la syntaxe pour faire comprendre à Git que vous parlez de HEAD. Par exemple, vous pouvez obtenir les mêmes résultats que précédemment en tapant git log origin/master.. - Git utilise HEAD si une des bornes est manquante.
VI-A-7-b. Emplacements multiples▲
La syntaxe double-point est pratique comme raccourci; mais peut-être souhaitez-vous utiliser plus d'une branche pour spécifier une révision, comme pour voir quels commits sont dans plusieurs branches mais qui sont absents de la branche courante. Git vous permets cela avec ^ or --not en préfixe de toute référence de laquelle vous ne souhaitez pas voir les commits. Les 3 commandes ci-après sont équivalentes :
$ git log refA..refB
$ git log ^refA refB
$ git log refB --not refAC'est utile car cela vous permets de spécifier plus de 2 références dans votre requête, ce que vous ne pouvez accomplir avec la syntaxe double-point. Par exemple, si vous souhaitez voir les commits qui sont accessibles depuis refA et refB mais pas depuis refC, vous pouvez taper ces 2 commandes :
$ git log refA refB ^refC
$ git log refA refB --not refCCeci vous fournit un système de requêtage des révisions très puissant, pour vous aider à saisir ce qui se trouve sur vos branches.
VI-A-7-c. Triple point▲
La dernière syntaxe majeure de sélection de plage de commits est la syntaxe triple-point, qui spécifie tous les commits accessible par l'une des deux référence, exclusivement. Toujours avec l'exemple d'historique à la figure 6-1, si vous voulez voir ce qui ce trouve sur master ou experiment mais pas sur les 2, exécutez :
$ git log master...experiment
F
E
D
CEncore une fois, cela vous donne un log normal mais ne vous montre les informations que pour ces quatre commits, dans l'ordre naturel des dates de commit.
Une option courante à utiliser avec la commande log dans ce cas est --left-right qui vous montre de quelle borne de la plage ce commit fait partie. Cela rend les données plus utiles :
$ git log --left-right master...experiment
< F
< E
> D
> CAvec ces outils, vous pourrez utiliser Git pour savoir quels commits inspecter.
VI-B. Mise en attente interactive▲
Git propose quelques scripts qui rendent les opérations en ligne de commande plus simple. Nous allons à présent découvrir des commandes interactives vous permettant de choisir les fichiers ou une partie d'un fichier à incorporer à un commit. Ces outils sont particulièrement pratiques si vous modifiez un large périmètre de fichiers et que vous souhaitez les commiter séparement plutôt que massivement. De la sorte, vous vous assurez que vos commits sont des ensembles cohérents et qu'ils peuvent être facilement revus par vos collaborateurs. Si vous exécutez git add avec l'option -i ou --interactive, Git rentre en mode interactif, affichant quelque chose comme :
$ git add -i
staged unstaged path
1: unchanged +0/-1 TODO
2: unchanged +1/-1 index.html
3: unchanged +5/-1 lib/simplegit.rb
*** Commands ***
1: status 2: update 3: revert 4: add untracked
5: patch 6: diff 7: quit 8: help
What now>Vous vous apercevrez que cette commande propose une vue bien différente de votre zone d'attente; en gros, c'est la même information que vous auriez obtenue avec git status mais en plus succint et plus instructif. Cela liste les modifications que vous avez mises en attente à gauche, et celles en cours à droite.
En dessous vient la section des commandes (*** Commands ). Vous pourrez y faire bon nombre de choses, notamment mettre en attente des fichiers, les enlever de la zone d'attente, mettre en attente des parties de fichiers, ajouter des fichiers non indexés, et vérifier les différences de ce que vous avez mis en attente.
VI-B-1. Mettre en attente des fichiers▲
Si vous tapez 2 ou u au prompt What now>, le script vous demande quels fichiers vous voulez mettre en attente :
What now> 2
staged unstaged path
1: unchanged +0/-1 TODO
2: unchanged +1/-1 index.html
3: unchanged +5/-1 lib/simplegit.rb
Update>>Pour mettre en attente les fichiers TODO et index.html, vous pouvez taper ces nombres :
Update>> 1,2
staged unstaged path
* 1: unchanged +0/-1 TODO
* 2: unchanged +1/-1 index.html
3: unchanged +5/-1 lib/simplegit.rb
Update>>Le caractère * au début de la ligne de chaque fichier indique que celui-ci est sélectionné. Si vous tapez Entrée sur une invite Update>> vide, Git prend tout ce qui est sélectionné et le met en attente pour vous :
Update>>
updated 2 paths
*** Commands ***
1: status 2: update 3: revert 4: add untracked
5: patch 6: diff 7: quit 8: help
What now> 1
staged unstaged path
1: +0/-1 nothing TODO
2: +1/-1 nothing index.html
3: unchanged +5/-1 lib/simplegit.rbÀ présent, vous pouvez voir que les fichiers TODO et index.html sont mis en attente (staged en anglais) et que simplgit.rb ne l'est toujours pas. Si vous souhaitez enlever de la zone d'attente le fichier TODO, utilisez 3 (ou r pour revert en anglais) :
*** Commands ***
1: status 2: update 3: revert 4: add untracked
5: patch 6: diff 7: quit 8: help
What now> 3
staged unstaged path
1: +0/-1 nothing TODO
2: +1/-1 nothing index.html
3: unchanged +5/-1 lib/simplegit.rb
Revert>> 1
staged unstaged path
* 1: +0/-1 nothing TODO
2: +1/-1 nothing index.html
3: unchanged +5/-1 lib/simplegit.rb
Revert>> [enter]
reverted one pathUn aperçu rapide à votre statut Git et vous pouvez voir que vous avez enlever de la zone d'attente le fichier TODO :
*** Commands ***
1: status 2: update 3: revert 4: add untracked
5: patch 6: diff 7: quit 8: help
What now> 1
staged unstaged path
1: unchanged +0/-1 TODO
2: +1/-1 nothing index.html
3: unchanged +5/-1 lib/simplegit.rbPour voir la modification que vous avez mise en attente, utilisez 6 ou d (pour diff en anglais). Cela vous affiche la liste des fichiers en attente et vous pouvez choisir ceux pour lesquels vous voulez consulter la différence. C'est équivalent à git diff --cached en ligne de commande :
*** Commands ***
1: status 2: update 3: revert 4: add untracked
5: patch 6: diff 7: quit 8: help
What now> 6
staged unstaged path
1: +1/-1 nothing index.html
Review diff>> 1
diff --git a/index.html b/index.html
index 4d07108..4335f49 100644
--- a/index.html
+++ b/index.html
@@ -16,7 +16,7 @@ Date Finder
<p id="out">...</p>
-<div id="footer">contact : support@github.com</div>
+<div id="footer">contact : email.support@github.com</div>
<script type="text/javascript">Avec ces commandes élémentaires, vous pouvez utiliser l'ajout interactif pour manipuler votre zone d'attente un peu plus facilement.
VI-B-2. Patches de Staging▲
Git est également capable de mettre en attente certaines parties d'un fichier. Par exemple, si vous modifiez en 2 endroits votre fichier simplegit.rb et que vous souhaitez mettre en attente l'une d'entre elles seulement, cela peut se faire très aisément avec Git. En mode interactif, tapez 5 ou p (pour patch en anglais). Git vous demandera quels fichiers vous voulez mettre en attente partiellement, puis, pour chaque section des fichiers sélectionnés, il affichera les parties de fichiers où il y a des différences et vous demandera si vous souhaitez les mettre en attente, un par un :
diff --git a/lib/simplegit.rb b/lib/simplegit.rb
index dd5ecc4..57399e0 100644
--- a/lib/simplegit.rb
+++ b/lib/simplegit.rb
@@ -22,7 +22,7 @@ class SimpleGit
end
def log(treeish = 'master')
- command("git log -n 25 #{treeish}")
+ command("git log -n 30 #{treeish}")
end
def blame(path)
Stage this hunk [y,n,a,d,/,j,J,g,e,?]?A cette étape, vous disposez de bon nombre d'options. ? vous liste les actions possibles, voici une traduction :
Mettre en attente cette partie [y,n,a,d,/,j,J,g,e,?]? ?
y - mettre en attente cette partie
n - ne pas mettre en attente cette partie
a - mettre en attente cette partie et toutes celles restantes dans ce fichier
d - ne pas mettre en attente cette partie ni aucune de celles restantes dans ce fichier
g - sélectionner un partie à voir
/ - chercher une partie correspondant à la regexp donnée
j - laisser cette partie non décidée, voir la prochaine partie non encore décidée
J - laisser cette partie non décidée, voir la prochaine partie
k - laisser cette partie non décidée, voir la partie non encore décidée précendente
K - laisser cette partie non décidée, voir la partie précédente
s - couper la partie courante en parties plus petites
e - modifier manuellement la partie courante
? - afficher l'aideEn règle générale, vous choisirez y ou n pour mettre en attente ou non chacun des blocs, mais tout mettre en attente pour certains fichiers ou remettre à plus tard le choix pour un bloc peut également être utile. Si vous mettez en attente une partie d'un fichier et laissez une autre partie non en attente, vous statut ressemblera à peu près à ceci :
What now> 1
staged unstaged path
1: unchanged +0/-1 TODO
2: +1/-1 nothing index.html
3: +1/-1 +4/-0 lib/simplegit.rbLe statut pour le fichier simplegit.rb est intéressant. Il vous montre que quelques lignes sont en attente et d'autres non. Vous avez mis partiellement ce fichier en attente. Dès lors, vous pouvez quitter l'ajout interactif et exécuter git commit pour commiter les fichiers partiellement en attente.
Enfin, vous pouvez vous passer du mode interactif pour mettre partiellement un fichier en attente; vous pouvez faire de même avec git add -p ou git add --patch en ligne de commande.
VI-C. La remise▲
Souvent, lorsque vous avez travaillé sur une partie de votre projet, les choses sont dans un état instable mais vous voulez changer de branches pour un peu de travailler sur autre chose. Le problème est que vous ne voulez pas consigner (commit) un travail à moitié fait seulement pour pouvoir y revenir plus tard. La réponse à cette problématique est la commande git stash.
Remiser prend l'état en cours de votre répertoire de travail, c'est-à-dire les fichiers modifiés et la zone d'attente, et l'enregistre dans la pile des modifications non finies que vous pouvez réappliquer à n'importe quel moment.
VI-C-1. Remiser votre travail▲
Pour démontrer cette possibilité, vous allez dans votre projet et commencez à travailler sur quelques fichiers et mettre en zone d'attente l'un de ces changements. Si vous exécutez git status, vous pouvez voir votre état instable:
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# modified: index.html
#
# Changed but not updated:
# (use "git add <file>..." to update what will be committed)
#
# modified: lib/simplegit.rb
#À ce moment là, vous voulez changer de branche, mais vous ne voulez pas encore consigner ce travail; vous allez donc remiser vos modifications. Pour créer une nouvelle remise sur votre pile, exécutez git stash :
$ git stash
Saved working directory and index state \
"WIP on master: 049d078 added the index file"
HEAD is now at 049d078 added the index file
(To restore them type "git stash apply")Votre répertoire de travail est propre :
$ git status
# On branch master
nothing to commit (working directory clean)À ce moment, vous pouvez facilement changer de branche et travailler autre part; vos modifications sont conservées dans votre pile. Pour voir quelles remises vous avez sauvegardées, vous pouvez utiliser la commande git stash list :
$ git stash list
stash@{0}: WIP on master: 049d078 added the index file
stash@{1}: WIP on master: c264051... Revert "added file_size"
stash@{2}: WIP on master: 21d80a5... added number to logDans ce cas, deux remises on été créées précédemment, vous avez donc accès à trois travaux remisés différents. Vous pouvez réappliquer celui que vous venez juste de remisé en utilisant la commande affichée dans la sortie d'aide de la première commande de remise : git stash apply. Si vous voulez appliquer une remise plus ancienne, vous pouvez la spécifier en la nommant, comme ceci : git stash apply stash@{2}. Si vous ne spécifier pas une remise, Git présume que vous voulez la remise la plus récente et essayes de l'appliquer.
$ git stash apply
# On branch master
# Changed but not updated:
# (use "git add <file>..." to update what will be committed)
#
# modified: index.html
# modified: lib/simplegit.rb
#Vous pouvez observer que Git remodifie les fichiers non consignés lorsque vous avez créé la remise. Dans ce cas, vous aviez un répertoire de travail propre lorsque vous avez essayer d'appliquer la remise, et vous l'avez fait sur la même branche que celle où vous l'aviez créée; mais avoir un répertoire de travail propre et l'appliquer sur la même branche n'est pas nécessaire pour réussir à appliquer une remise. Vous pouvez très bien créer une remise sur une branche, changer de branche et essayer d'appliquer les modifications. Vous pouvez même avoir des fichiers modifiés et non consignés dans votre répertoire de travail quand vous appliquez une remise, Git vous fournit les conflits de fusions si quoique ce soit ne s'applique pas proprement.
Par défaut, les modifications de vos fichiers sont réappliqués, mais pas les mises en attente. Pour cela, vous devez exécutez la commande git stash apply avec l'option --index pour demandez à Git d'essayer de réappliquer les modifications de votre zone d'attente. Si vous exécutez cela à la place de la commande précédente, vous vous retrouvez dans la position d'origine de la remise :
$ git stash apply --index
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# modified: index.html
#
# Changed but not updated:
# (use "git add <file>..." to update what will be committed)
#
# modified: lib/simplegit.rb
#L'option apply essaye seulement d'appliquer le travail remisé, vous aurez toujours la remise dans votre pile. Pour la supprimer, vous pouvez exécuter git stash drop avec le nom de la remise à supprimer :
$ git stash list
stash@{0}: WIP on master: 049d078 added the index file
stash@{1}: WIP on master: c264051... Revert "added file_size"
stash@{2}: WIP on master: 21d80a5... added number to log
$ git stash drop stash@{0}
Dropped stash@{0} (364e91f3f268f0900bc3ee613f9f733e82aaed43)Vous pouvez également exécutez git stash pop pour appliquer et supprimer immédiatement la remise de votre pile.
VI-C-2. Défaire l'effet d'une remise▲
Dans certains cas, il est souhaitable de pouvoir appliquer une modification remisée, réaliser d'autres modifications, puis défaire les modifications de la remise. Git ne fournit pas de commande stash unapply mais il est possible d'obtenir le même effet en extrayant les modifications qui constituent la remise et en appliquant leur inverse :
$ git stash show -p stash@{0} | git apply -RIci aussi, si la remise n'est pas indiquée, Git utilise la plus récente.
$ git stash show -p | git apply -RLa création d'un alias permettra d'ajouter effectivement la commande stash-unapply à votre Git. Par exemple :
$ git config --global alias.stash-unapply '!git stash show -p | git apply -R'
$ git stash
$ #... work work work
$ git stash-unapplyVI-C-3. Créer une branche depuis une remise▲
Si vous remiser votre travail, l'oubliez pendant un temps en continuant sur la branche où vous avez créé la remise, vous pouvez avoir un problème en réappliquant le travail. Si l'application de la remise essaye de modifier un fichier que vous avez modifié depuis, vous allez obtenir des conflits de fusion et vous devrez essayer de les résoudre. Si vous voulez un moyen plus facile de tester une nouvelle fois les modifications remisées, vous pouvez exécuter git stash branch, qui créera une nouvelle branche à votre place, récupérant le commit où vous étiez lorsque vous avez créé la remise, réappliquera votre travail dedans, et supprimera finalement votre remise si cela a réussi :
$ git stash branch testchanges
Switched to a new branch "testchanges"
# On branch testchanges
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# modified: index.html
#
# Changed but not updated:
# (use "git add <file>..." to update what will be committed)
#
# modified: lib/simplegit.rb
#
Dropped refs/stash@{0} (f0dfc4d5dc332d1cee34a634182e168c4efc3359)C'est un bon raccourci pour récupérer du travail remisé facilement et de pouvoir travailler dessus dans une nouvelle branche.
VI-D. Réécrire l'historique▲
Bien souvent, lorsque vous travaillez avec Git, vous souhaitez modifier votre historique de consignation pour une raison quelconque. Une des choses merveilleuses de Git est qu'il vous permet de prendre des décisions le plus tard possible. Vous pouvez décider quels fichiers vont dans quel commit avant que vous ne consigniez la zone d'attente, vous pouvez décider que vous ne voulez pas encore montrer que vous travailler sur quelque chose avec les remises, et vous pouvez réécrire les commits afin déjà sauvegardé pour qu'ils ressemblent à quelque chose d'autre. Cela peut signifier changer l'ordre des commits, modifier les messages ou modifier les fichiers appartenant au commit, rassembler ou séparer des commits, ou supprimer complètement des commits; tout ceci avant de les partager avec les autres.
Danc cette section, nous expliquerons comment accomplir ces tâches très utiles pour que vous pussiez faire ressembler votre historique de consignation de la manière que vous voulez avant de le partager avec autrui.
VI-D-1. Modifier la dernière consignation▲
Modifier votre dernière consignation est probablement la plus habituelle réécriture de l'historique que vous allez faire. Vous voudrez souvent faire deux choses basiques à votre dernier commit : modifier le message de consignation, ou changer le contenu que vous avez enregistré en ajoutant, modifiant ou supprimant des fichiers.
Si vous voulez seulement modifier votre dernier message de consignation, c'est vraiment simple :
$ git commit --amendCela vous ouvre votre éditeur de texte contenant votre dernier message, prêt à être modifié. Lorsque vous sauvegardez et fermez l'éditeur, Git enregistre la nouvelle consignation contenant le message et en fait votre dernier commit.
Si vous avez vouler modifier le contenu de votre consignation, en ajoutant ou modifiant des fichiers, sûrement parce que vous avez oublié d'ajouter les fichiers nouvellement créés quand vous avez consigné la première fois, la procédure fonctionne grosso-modo de la même manière. Vous mettez les modifications que vous voulez en attente en exécutant git add ou git rm, et le prochain git commit --amend prendra votre zone d'attente courante et en fera le contenu de votre nouvelle consignation.
Vous devez être prudent avec cette technique car votre modification modifie également le SHA-1 du commit. Cela ressemble à un tout petit rebase. Ne modifiez pas votre dernière consignation si vous l'avez déjà publié !
VI-D-2. Modifier plusieurs messages de consignation▲
Pour modifier une consignation qui est plus loin dans votre historique, vous devez utilisez des outils plus complexes. Git ne contient pas d'outil de modification d'historique, mais vous pouvez utiliser l'outil rebase pour rebaser une suite de commits depuis la branche HEAD plutôt que de les déplacer vers une autre branche. Avec l'outil rebase interactif, vous pouvez vous arrêter après chaque commit que vous voulez modifiez et changer le message, ajouter des fichiers ou quoique ce soit que vous voulez. Vous pouvez exécuter rebase interactivement en ajoutant l'option -i à git rebase. Vous devez indiquer jusqu'à quand remonter dans votre historique en donnant à la commande le commit sur lequel vous voulez vous rebaser.
Par exemple, si vous voulez modifier les 3 derniers messages de consignation, ou n'importe lequel des messages dans ce groupe, vous fournissez à git rebase -i le parent du dernier commit que vous voulez éditer, qui est HEAD~2^ or HEAD~3. Il peut être plus facile de ce souvenir de ~3, car vous essayer de modifier les 3 derniers commits, mais gardez à l'esprit que vous désignez le 4e, le parent du dernier commit que vous voulez modifier :
$ git rebase -i HEAD~3Souvenez-vous également que ceci est une commande de rebasement, chaque commit include dans l'intervalle HEAD~3..HEAD sera réécrit, que vous changiez le message ou non. N'incluez pas dans cette commande de commit que vous avez déjà poussé sur un serveur central. Le faire entrainera la confusion chez les autres développeurs en leur fournissant une version altérée des mêmes modifications.
Exécuter cette commande vous donne la liste des consignations dans votre éditeur de texte, ce qui ressemble à :
pick f7f3f6d changed my name a bit
pick 310154e updated README formatting and added blame
pick a5f4a0d added cat-file
# Rebase 710f0f8..a5f4a0d onto 710f0f8
#
# Commands:
# p, pick = use commit
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
#
# If you remove a line here THAT COMMIT WILL BE LOST.
# However, if you remove everything, the rebase will be aborted.
#Il est important de signaler que les commits sont listés dans l'ordre opposé que vous voyez normalement en utilisant la commande log. Si vous exécutez la commande log, vous verrez quelque chose de ce genre :
$ git log --pretty=format:"%h %s" HEAD~3..HEAD
a5f4a0d added cat-file
310154e updated README formatting and added blame
f7f3f6d changed my name a bitRemarquez l'ordre inverse. Le rebasage interactif va créer un script à exécuter. Il commencera au commit que vous spécifiez sur la ligne de commande (HEAD~3) et refait les modifications introduites dans chacun des commits du début à la fin. Il ordonne donc le plus vieux au début, plutôt que le plus récent, car c'est celui qu'il refera en premier.
Vous devez éditer le script afin qu'il s'arrête au commit que vous voulez modifier. Pour cela, remplacer le mot “pick par le mot “edit pour chaque commit après lequel vous voulez que le script s'arrête. Par exemple, pour modifier uniquement le message du troisième commit, vous modifiez le fichier pour ressembler à :
edit f7f3f6d changed my name a bit
pick 310154e updated README formatting and added blame
pick a5f4a0d added cat-fileAu moment où vous sauvegardez et quittez l'éditeur, Git revient au dernier commit de cette liste et vous laisse sur une ligne de commande avec le message suivant :
$ git rebase -i HEAD~3
Stopped at 7482e0d... updated the gemspec to hopefully work better
You can amend the commit now, with
git commit --amend
Once you're satisfied with your changes, run
git rebase --continueCes instructions vous disent exactement quoi faire. Entrez :
$ git commit --amendModifiez le message de commit et quittez l'éditeur. Puis exécutez :
$ git rebase --continueCette commande appliquera les deux autres commits automatiquement, c'est fait. Si vous remplacez “pick en “edit sur plusieurs lignes, vous pouvez répéter ces étapes pour chaque commit que vous avez remplacé pour modification. Chaque fois, Git s'arrêtera, vous laissant modifier le commit et continuera lorsque vous aurez fini.
VI-D-3. Réordonner les commits▲
Vous pouvez également utilisez les rebasages interactifs afin de réordonner ou supprimer entièrement des commits. Si vous voulez supprimer le commit “added cat-file et modifier l'ordre dans lequel les deux autres commits se trouvent dans l'historique, vous pouvez modifier le script de rebasage :
pick f7f3f6d changed my name a bit
pick 310154e updated README formatting and added blame
pick a5f4a0d added cat-fileafin qu'il ressemble à ceci :
pick 310154e updated README formatting and added blame
pick f7f3f6d changed my name a bitLorsque vous sauvegardez et quittez l'éditeur, Git remet votre branche au niveau du parent de ces commits, applique 310154e puis f7f3f6d et s'arrête. Vous venez de modifier l'ordre de ces commits et de supprimer entièrement le commit “added cat-file.
VI-D-4. Rassembler des commits▲
Il est également possible de prendre une série de commits et de les rassembler en un seul avec l'outil de rebasage interactif. Le script affiche des instructions utiles dans le message de rebasage :
#
# Commands:
# p, pick = use commit
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
#
# If you remove a line here THAT COMMIT WILL BE LOST.
# However, if you remove everything, the rebase will be aborted.
#Si, à la place de “pick ou “edit, vous spécifiez “squash, Git applique cette modification et la modification juste précédente et fusionne les messages de consignation. Donc, si vous voulez faire un seul commit de ces trois consignations, vous faites en sorte que le script ressemble à ceci :
pick f7f3f6d changed my name a bit
squash 310154e updated README formatting and added blame
squash a5f4a0d added cat-fileLorsque vous sauvegardez et quittez l'éditeur, Git applique ces trois modifications et vous remontre l'éditeur contenant maintenant la fusion des 3 messages de consignation :
# This is a combination of 3 commits.
# The first commit's message is:
changed my name a bit
# This is the 2nd commit message:
updated README formatting and added blame
# This is the 3rd commit message:
added cat-fileLorsque vous sauvegardez cela, vous obtenez un seul commit amenant les modifications des trois commits précédents.
VI-D-5. Diviser un commit▲
Pour diviser un commit, il doit être défait, puis partiellement mis en zone d'attente et consigner autant de fois que vous voulez pour en finir avec lui. Par exemple, supposons que vous voulez diviser le commit du milieu dans l'exemple des trois commits précédents. Plutôt que “updated README formatting and added blame, vous voulez le diviser en deux commits : “updated README formatting pour le premier, et “added blame pour le deuxième. Vous pouvez le faire avec le script rebase -i en remplaçant l'instruction sur le commit que vous voulez divisez en “edit :
pick f7f3f6d changed my name a bit
edit 310154e updated README formatting and added blame
pick a5f4a0d added cat-filePuis, lorsque le script vous laissera accès à la ligne de commande, vous annulerez (reset) ce commit, vous reprendrez les modifications que vous voulez pour créer plusieurs commits. En reprenant l'exemple, lorsque vous sauvegardez et quittez l'éditeur, Git revient au parent de votre premier commit de votre liste, applique le premier commit (f7f3f6d), applique le deuxième (310154e), et vous laisse accès à la console. Là, vous pouvez faire une réinitialisation mélangée (mixed reset) de ce commit avec git reset HEAD^, qui défait ce commit et laisse les fichiers modifiés non mis en attente. Maintenant, vous pouvez mettre en attente et consigner les fichiers sur plusieurs consignations, et exécuter git rebase --continue quand vous avez fini :
$ git reset HEAD^
$ git add README
$ git commit -m 'updated README formatting'
$ git add lib/simplegit.rb
$ git commit -m 'added blame'
$ git rebase --continueGit applique le dernier commit (a5f4a0d) de votre script, et votre historique ressemblera alors à :
$ git log -4 --pretty=format:"%h %s"
1c002dd added cat-file
9b29157 added blame
35cfb2b updated README formatting
f3cc40e changed my name a bitUne fois encore, ceci modifie les empreintes SHA de tous les commits dans votre liste, soyez donc sûr qu'aucun commit de cette liste ait été poussé dans un dépôt partagé.
VI-D-6. L'option nucléaire : filter-branch▲
Il existe une autre option de la réécriture d'historique que vous pouvez utiliser si vous avez besoin de réécrire un grand nombre de commits d'une manière scriptable; par exemple, modifier globalement votre adresse mail ou supprimer un fichier de tous les commits. La commande est filter-branch, et elle peut réécrire des pans entiers de votre historique, vous ne devriez donc pas l'utiliser à moins que votre projet ne soit pas encore public ou que personne n'a encore travaillé sur les commits que vous allez réécrire. Cependant, cela peut être très utile. Vous allez maintenant apprendre quelques usages communs pour vous donner une idée de ses capacités.
VI-D-6-a. Supprimer un fichier de chaque commit▲
Cela arrive asser fréquemment. Quelqu'un a accidentellement commité un énorme fichier binaire avec une commande git add . irréfléchie, and vous voulez le supprimer partout. Vous avez peut-être consigné un fichier contenant un mot de passe, et que vous voulez rendre votre projet open source. filter-branch est l'outil que vous voulez probablement utiliser pour nettoyer votre historique entier. Pour supprimer un fichier nommé “passwords.txt de tout votre historique, vous pouvez utiliser l'option --tree-filter de filter-branch :
$ git filter-branch --tree-filter 'rm -f passwords.txt' HEAD
Rewrite 6b9b3cf04e7c5686a9cb838c3f36a8cb6a0fc2bd (21/21)
Ref 'refs/heads/master' was rewrittenL'option --tree-filter exécute la commande spécifiée pour chaque commit et les reconsigne ensuite Dans le cas présent, vous supprimez le fichier nommé “passwords.txt de chaque contenu, qu'il existait ou non. Si vous voulez supprimez tous les fichiers temporaires des éditeurs consignés accidentellement, vous pouvez exécuter une commande telle que git filter-branch --tree-filter 'rm -f *~' HEAD.
Vous pourrez alors regarder Git réécrire l'arbre des commits et reconsigner à chaque fois, pour finir en modifiant la référence de la branche. C'est généralement une bonne idée de le faire dans un branche de test puis de faire une forte réinitialisation (hard-reset) de votre branche master si le résultat vous convient. Pour exécuter filter-branch sur toutes vos branches, vous pouvez ajouter --all à la commande.
VI-D-6-b. Faire d'un sous-répertoire la nouvelle racine▲
Supposons que vous avez importer votre projet depuis un autre système de gestion de configuration et que vous avez des sous-répertoires qui n'ont aucun sens (trunk, tags, etc). Si vous voulez faire en sorte que le sous-répertoire trunk soit la nouvelle racine de votre projet pour tous les commits, filter-branch peut aussi vous aider à le faire :
$ git filter-branch --subdirectory-filter trunk HEAD
Rewrite 856f0bf61e41a27326cdae8f09fe708d679f596f (12/12)
Ref 'refs/heads/master' was rewrittenMaintenant votre nouvelle racine est remplacé par le contenu du répertoire trunk. De plus, Git supprimera automatiquement les commits qui n'affectent pas ce sous-répertoire.
VI-D-6-c. Modifier globalement l'adresse mail▲
Un autre cas habituel est que vous oubliez d'exécuter git config pour configurer votre nom et votre adresse mail avant de commencer à travailler, ou vous voulez peut-être rendre un projet du boulot open source et donc changer votre adresse professionnelle pour celle personnelle. Dans tous les cas, vous pouvez modifier l'adresse mail dans plusieurs commits avec un script filter-branch Vous devez faire attention de ne changer que votre adresse mail, utilisez donc --commit-filter :
$ git filter-branch --commit-filter '
if [ "$GIT_AUTHOR_EMAIL" = "schacon@localhost" ];
then
GIT_AUTHOR_NAME="Scott Chacon";
GIT_AUTHOR_EMAIL="schacon@example.com";
git commit-tree "$@";
else
git commit-tree "$@";
fi' HEADCela passe sur chaque commit et le réécrit pour avoir votre nouvelle adresse. Mais puisque les commits contiennent l'empreinte SHA-1 de leur parent, cette commande modifie tous les commits dans votre historique, pas seulement ceux correspondant à votre adresse mail.
VI-E. Deboguer avec Git▲
Git fournit aussi quelques outils pour vous aider à déboguer votre projet. Puisque Git est conçu pour fonctionner avec pratiquement tout type de projet, ces outils sont plutôt génériques, mais ils peuvent souvent vous aider à traquer un bogue ou au moins cerner où cela tourne mal.
VI-E-1. Fichier annoté▲
Si vous traquez un bogue dans votre code et que vous voulez savoir quand il est apparu et pourquoi, annoter les fichiers est souvent le meilleur moyen. Cela vous montre le dernier commit qui a modifié chaque ligne de votre fichier. Donc, si vous voyez une méthode dans votre code qui est boguée, vous pouvez annoter le fichier avec git blame pour voir quand chaque ligne de la méthode a été modifiée pour la dernière fois et par qui. Cet exemple utilise l'option -L pour limiter la sortie des lignes 12 à 22 :
$ git blame -L 12,22 simplegit.rb
^4832fe2 (Scott Chacon 2008-03-15 10:31:28 -0700 12) def show(tree = 'master')
^4832fe2 (Scott Chacon 2008-03-15 10:31:28 -0700 13) command("git show #{tree}")
^4832fe2 (Scott Chacon 2008-03-15 10:31:28 -0700 14) end
^4832fe2 (Scott Chacon 2008-03-15 10:31:28 -0700 15)
9f6560e4 (Scott Chacon 2008-03-17 21:52:20 -0700 16) def log(tree = 'master')
79eaf55d (Scott Chacon 2008-04-06 10:15:08 -0700 17) command("git log #{tree}")
9f6560e4 (Scott Chacon 2008-03-17 21:52:20 -0700 18) end
9f6560e4 (Scott Chacon 2008-03-17 21:52:20 -0700 19)
42cf2861 (Magnus Chacon 2008-04-13 10:45:01 -0700 20) def blame(path)
42cf2861 (Magnus Chacon 2008-04-13 10:45:01 -0700 21) command("git blame #{path}")
42cf2861 (Magnus Chacon 2008-04-13 10:45:01 -0700 22) endRemarquez que le premier champ est le SHA-1 partiel du dernier commit a avoir modifié la ligne. Les deux champs suivants sont des valeurs extraites du commit : l'auteur et la date du commit, vous pouvez donc facilement voir qui a modifié la ligne et quand. Ensuite arrive le numéro de ligne et son contenu. Remarquez également les lignes dont le commit est ^4832fe2, elles désignent les lignes qui étaient dans la version du fichier lors du premier commit de ce fichier. Ce commit contient le premier ajout de ce fichier, et ces lignes n'ont pas été modifiées depuis. Tout ça est un peu confus, parce que vous connaissez maintenant au moins trois façons différentes que Git interprète ^ pour modifier l'empreinte SHA, mais au moins, vous savez ce qu'il signifie ici.
Une autre chose sympa sur Git, c'est qu'il ne suit pas explicitement les renommages de fichier. Il enregistre les contenus puis essaye de deviner ce qui a été renommé implicitement, après coup. Ce qui nous permet d'utiliser cette fonctionnalité intéressante pour suivre toute sorte de mouvement de code. Si vous passez -C à git blame, Git analyse le fichier que vous voulez annoter et essaye de devenir d'où les bouts de code proviennent par copie ou déplacement. Récemment, j'ai remanié un fichier nommé GITServerHandler.m en le divisant en plusieurs fichiers, dont le fichier GITPackUpload.m. En annotant GITPackUpload.m avec l'option -C, je peux voir quelles sections de code en est originaire :
$ git blame -C -L 141,153 GITPackUpload.m
f344f58d GITServerHandler.m (Scott 2009-01-04 141)
f344f58d GITServerHandler.m (Scott 2009-01-04 142) - (void) gatherObjectShasFromC
f344f58d GITServerHandler.m (Scott 2009-01-04 143) {
70befddd GITServerHandler.m (Scott 2009-03-22 144) //NSLog(@"GATHER COMMI
ad11ac80 GITPackUpload.m (Scott 2009-03-24 145)
ad11ac80 GITPackUpload.m (Scott 2009-03-24 146) NSString *parentSha;
ad11ac80 GITPackUpload.m (Scott 2009-03-24 147) GITCommit *commit = [g
ad11ac80 GITPackUpload.m (Scott 2009-03-24 148)
ad11ac80 GITPackUpload.m (Scott 2009-03-24 149) //NSLog(@"GATHER COMMI
ad11ac80 GITPackUpload.m (Scott 2009-03-24 150)
56ef2caf GITServerHandler.m (Scott 2009-01-05 151) if(commit) {
56ef2caf GITServerHandler.m (Scott 2009-01-05 152) [refDict setOb
56ef2caf GITServerHandler.m (Scott 2009-01-05 153)C'est vraiment utile, non ? Normalement, vous obtenez comme commit original, celui dont votre code a été copié, puisque ce fut la première fois que vous avez touché à ces lignes dans ce fichier. Git vous montre le commit d'origine, celui où vous avez écrit ces lignes, même si c'était dans un autre fichier.
VI-E-2. La recherche dichotomique▲
Annoter un fichier peut aider si vous savez déjà où le problème se situe. Si vous ne savez pas ce qui a cassé le code, il peut y avoir des douzaines, voire des centaines de commits depuis le dernier état où votre code fonctionnait, et vous aimeriez certainement exécuter git bisect pour l'aide qu'il procure. La commande bisect effectue une recherche par dichotomie dans votre historique pour vous aider à identifier aussi vite que possible quel commit a vu le bogue naitre.
Disons que vous venez juste de pousser une version finale de votre code en production, vous récupérez un rapport de bogue à propos de quelque chose qui n'arrivait pas dans votre environnement de développement, et vous n'arrivez pas à trouver pourquoi votre code le fait. Vous retournez sur votre code, et il apparait que vous pouvez reproduire le bogue, mais vous ne savez pas ce qui se passe mal. Vous pouvez faire une recherche par dichotomie pour trouver ce qui ne va pas. D'abord, exécutez git bisect start pour démarrer la procédure, puis utilisez la commande git bisect bad pour dire que le commit courant est bogué. Ensuite, dites à bisect quand le code fonctionnait, en utilisant git bisect good [bonne_version] :
$ git bisect start
$ git bisect bad
$ git bisect good v1.0
Bisecting: 6 revisions left to test after this
[ecb6e1bc347ccecc5f9350d878ce677feb13d3b2] error handling on repoGit trouve qu'il y a environ 12 commits entre celui que vous avez marqué comme le dernier bon connu (v1.0) et la version courante qui n'est pas bonne, et il a récupéré le commit au milieu à votre place. À ce moment, vous pouvez dérouler vos tests pour voir si le bogue existait dans ce commit. Si c'est le cas, il a été introduit quelque part avant ce commit médian, sinon, il l'a été évidemment introduit après. Il apparait que le bogue ne se reproduit pas ici, vous le dites à Git en tapant git bisect good et continuez votre périple :
$ git bisect good
Bisecting: 3 revisions left to test after this
[b047b02ea83310a70fd603dc8cd7a6cd13d15c04] secure this thingVous êtes maintenant sur un autre commit, à mi-chemin entre celui que vous venez de tester et votre commit bogué. Vous exécutez une nouvelle fois votre test et trouvez que ce commit est bogué, vous le dites à Git avec git bisect bad :
$ git bisect bad
Bisecting: 1 revisions left to test after this
[f71ce38690acf49c1f3c9bea38e09d82a5ce6014] drop exceptions tableCe commit-ci est bon, et Git a maintenant toutes les informations dont il a besoin pour déterminer où le bogue a été créé. Il vous affiche le SHA-1 du premier commit bogué, quelques informations du commit et quels fichiers ont été modifiés dans celui-ci, vous pouvez donc trouver ce qui s'est passé pour créer ce bogue :
$ git bisect good
b047b02ea83310a70fd603dc8cd7a6cd13d15c04 is first bad commit
commit b047b02ea83310a70fd603dc8cd7a6cd13d15c04
Author: PJ Hyett <pjhyett@example.com>
Date: Tue Jan 27 14:48:32 2009 -0800
secure this thing
:040000 040000 40ee3e7821b895e52c1695092db9bdc4c61d1730
f24d3c6ebcfc639b1a3814550e62d60b8e68a8e4 M configLorsque vous avez fini, vous devez exécuter git bisect reset pour réinitialiser votre HEAD où vous étiez avant de commencer, ou vous travaillerez dans un répertoire de travail non clairement défini :
$ git bisect resetC'est un outil puissant qui vous aidera à vérifier des centaines de commits en quelques minutes. En réalité, si vous avez un script qui sort avec une valeur 0 s'il est bon et autre chose sinon, vous pouvez même automatiser git bisect. Premièrement vous lui spécifiez l'intervalle en lui fournissant les bon et mauvais commits connus. Vous pouvez faire cela en une ligne en les entrant à la suite de la commande bisect start, le mauvais commit d'abord :
$ git bisect start HEAD v1.0
$ git bisect run test-error.shCela exécute automatiquement test-error.sh sur chaque commit jusqu'à ce que Git trouve le premier commit bogué. Vous pouvez également exécuter des commandes comme make ou make tests ou quoique ce soit qui exécute des tests automatisés à votre place.
VI-F. Sous-modules▲
Il arrive souvent lorsque vous travaillez sur un projet, que vous devez utilisez un autre projet comme dépendance. Cela peut être une librairie qui est développée par une autre équipe ou que vous développez séparemment pour l'utiliser dans plusieurs projets parents. Ce scénario provoque un problème habituel : vous voulez être capable de gérer deux projets séparés tout en utilisant un dans l'autre.
Voici un exemple. Supposons que vous développez un site web et que vous créez des flux Atom. Plutôt que d'écrire votre propre code de génération Atom, vous décidez d'utiliser une librairie. Vous allez vraisemblablement devoir soit inclure ce code depuis un gestionnaire partagé comme CPAN ou Ruby gem, soit copier le code source dans votre propre arborescence de projet. Le problème d'inclure la librairie en tant que librairie externe est qu'il est difficile de la personnaliser de quelque manière que ce soit et encore plus de la déployer, car vous devez vous assurer de la disponibilité de la librairie chez chaque client. Mais le problème d'inclure le code dans votre propre projet est que n'importe quelle personnalisation que vous faites est difficile à fusionner lorsque les modifications du développement principal arrivent.
Git gère ce problème avec les sous-modules. Les sous-modules vous permettent de gérer un dépôt Git comme un sous-répertoire d'un autre dépôt Git. Cela vous laisse la possibilité de cloner un dépôt dans votre projet et de garder isolés les commits de ce dépôt.
VI-F-1. Démarrer un sous-module▲
Supposons que vous voulez ajouter la librairie Rack (un serveur d'application web en Ruby) à votre projet, avec la possibilité de gérer vos propres changements à celle-ci mais en continuant de fusionner avec la branche principale. La première chose que vous devez faire est de cloner le dépôt externe dans votre sous-répertoire. Ajouter des projets externes comme sous-modules de votre projet se fait avec la commande git submodule add :
$ git submodule add git://github.com/chneukirchen/rack.git rack
Initialized empty Git repository in /opt/subtest/rack/.git/
remote: Counting objects: 3181, done.
remote: Compressing objects: 100% (1534/1534), done.
remote: Total 3181 (delta 1951), reused 2623 (delta 1603)
Receiving objects: 100% (3181/3181), 675.42 KiB | 422 KiB/s, done.
Resolving deltas: 100% (1951/1951), done.Vous avez maintenant le projet Rack dans le sous-répertoire rack à l'intérieur de votre propre projet. Vous pouvez aller dans ce sous-répertoire, effectuer des modifications, ajouter votre propre dépôt distant pour y pousser vos modifications, récupérer et fusionner depuis le dépôt originel, et plus encore. Si vous exécutez git status juste après avoir ajouter le sous-module (donc dans le répertoire parent du répertoire rack), vous verrez deux choses :
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: .gitmodules
# new file: rack
#Premièrement, vous remarquerez le fichier .gitmodules. C'est un fichier de configuration sauvegardant la liaison entre l'URL du projet et le sous-répertoire local où vous l'avez mis :
$ cat .gitmodules
[submodule "rack"]
path = rack
url = git://github.com/chneukirchen/rack.gitSi vous avez plusieurs sous-modules, vous aurez plusieurs entrées dans ce fichier. Il est important de noter que ce fichier est en gestion de version comme vos autres fichiers, à l'instar de votre fichier .gitignore. Il est poussé et tiré comme le reste de votre projet. C'est également le moyen que les autres personnes qui clonent votre projet peuvent savoir où récupérer le projet du sous-module.
L'autre information dans la sortie de git status est l'entrée rack. Si vous exécutez git diff, vous verrez quelque chose d'intéressant :
$ git diff --cached rack
diff --git a/rack b/rack
new file mode 160000
index 0000000..08d709f
--- /dev/null
+++ b/rack
@@ -0,0 +1 @@
+Subproject commit 08d709f78b8c5b0fbeb7821e37fa53e69afcf433Même si rack est un sous répertoire de votre répertoire de travail, Git le voit comme un sous-module et ne suit pas son contenu (si vous n'êtes pas dans ce répertoire). En échange, Git l'enregistre comme un commit particulier de ce dépôt. Lorsque vous faites des modifications et des consignations dans ce sous-répertoire, le super-projet (le projet contenant le sous-module) remarque que la branche HEAD a changé et enregistre le commit exacte dans lequel il se trouve à ce moment. De cette manière, lorsque d'autre clone ce super-projet, ils peuvent recréer exactement le même environnement.
Un autre point important avec les sous-modules : Git enregistre le commit exact où ils se trouvent. Vous ne pouvez pas enregistrer un module comme étant en branche master ou n'importe quelle autre référence symbolique.
Au moment de commiter, vous voyez quelque chose comme :
$ git commit -m 'first commit with submodule rack'
[master 0550271] first commit with submodule rack
2 files changed, 4 insertions(+), 0 deletions(-)
create mode 100644 .gitmodules
create mode 160000 rackRemarquez le mode 160000 pour l'entrée rack. C'est un mode spécial de Git qui signifie globalement que vous êtes en train d'enregistrer un commit comme un répertoire plutôt qu'un sous-répertoire ou un fichier.
Vous pouvez traiter le répertoire rack comme un projet séparé et mettre à jour votre super-projet de temps en temps avec une référence au dernier commit de ce sous-projet. Toutes les commandes Git fonctionnent indépendamment dans les deux répertoires :
$ git log -1
commit 0550271328a0038865aad6331e620cd7238601bb
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Apr 9 09:03:56 2009 -0700
first commit with submodule rack
$ cd rack/
$ git log -1
commit 08d709f78b8c5b0fbeb7821e37fa53e69afcf433
Author: Christian Neukirchen <chneukirchen@gmail.com>
Date: Wed Mar 25 14:49:04 2009 +0100
Document version changeVI-F-2. Cloner un projet avec des sous-modules▲
Maintenant, vous allez apprendre à cloner un projet contenant des sous-modules. Quand vous récupérez un tel projet, vous obtenez les différents répertoires qui contiennent les sous-modules, mais encore aucun des fichiers :
$ git clone git://github.com/schacon/myproject.git
Initialized empty Git repository in /opt/myproject/.git/
remote: Counting objects: 6, done.
remote: Compressing objects: 100% (4/4), done.
remote: Total 6 (delta 0), reused 0 (delta 0)
Receiving objects: 100% (6/6), done.
$ cd myproject
$ ls -l
total 8
-rw-r--r-- 1 schacon admin 3 Apr 9 09:11 README
drwxr-xr-x 2 schacon admin 68 Apr 9 09:11 rack
$ ls rack/
$Le répertoire rack est présent mais vide. Vous devez exécuter deux commandes : git submodule init pour initialiser votre fichier local de configuration, et git submodule update pour tirer toutes les données de ce projet et récupérer le commit approprié tel que listé dans votre super-projet :
$ git submodule init
Submodule 'rack' (git://github.com/chneukirchen/rack.git) registered for path 'rack'
$ git submodule update
Initialized empty Git repository in /opt/myproject/rack/.git/
remote: Counting objects: 3181, done.
remote: Compressing objects: 100% (1534/1534), done.
remote: Total 3181 (delta 1951), reused 2623 (delta 1603)
Receiving objects: 100% (3181/3181), 675.42 KiB | 173 KiB/s, done.
Resolving deltas: 100% (1951/1951), done.
Submodule path 'rack': checked out '08d709f78b8c5b0fbeb7821e37fa53e69afcf433'Votre répertoire rack est maintenant dans l'état exacte dans lequel il était la dernière fois que vous avez consigné. Si un autre développeur modifie le code de rack et consigne, que vous récupériez (pull) cette référence et que vous fusionniez, vous obtiendrez quelque chose d'un peu étrange :
$ git merge origin/master
Updating 0550271..85a3eee
Fast forward
rack | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)
[master*]$ git status
# On branch master
# Changed but not updated:
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working directory)
#
# modified: rack
#En réalité, vous n'avez fusionné que la modification de la référence de votre sous-module, mais Git n'a pas mis à jour le code dans le répertoire du sous-module, de ce fait, cela ressemble à un état “en cours dans votre répertoire de travail :
$ git diff
diff --git a/rack b/rack
index 6c5e70b..08d709f 160000
--- a/rack
+++ b/rack
@@ -1 +1 @@
-Subproject commit 6c5e70b984a60b3cecd395edd5b48a7575bf58e0
+Subproject commit 08d709f78b8c5b0fbeb7821e37fa53e69afcf433La cause de tout cela, c'est que la référence pour votre sous-module ne correspond pas à ce qu'il y a actuellement dans son répertoire. Pour corriger ça, vous devez exécuter un nouvelle fois git submodule update :
$ git submodule update
remote: Counting objects: 5, done.
remote: Compressing objects: 100% (3/3), done.
remote: Total 3 (delta 1), reused 2 (delta 0)
Unpacking objects: 100% (3/3), done.
From git@github.com:schacon/rack
08d709f..6c5e70b master -> origin/master
Submodule path 'rack': checked out '6c5e70b984a60b3cecd395edd5b48a7575bf58e0'Vous devez faire cela à chaque fois que vous récupérez une modification du sous-module dans le projet principal. C'est étrange, mais ça fonctionne.
Un problème habituel peut survenir lorsqu'un développeur modifie localement un sous-module, mais ne le pousse pas sur un serveur public. Puis, il consigne une référence à cet état non public et pousse le super-projet. Lorsque les autres développeurs exécutent git submodule update, le système dans le sous-module ne trouve pas le commit qui est référencé, car il existe uniquement sur le système du premier développeur. Dans ce cas, vous verrez une erreur de ce style :
$ git submodule update
fatal: reference isn't a tree: 6c5e70b984a60b3cecd395edd5b48a7575bf58e0
Unable to checkout '6c5e70b984a60b3cecd395edd5ba7575bf58e0' in submodule path 'rack'Vous devez regarder qui a modifié le sous-module en dernier :
$ git log -1 rack
commit 85a3eee996800fcfa91e2119372dd4172bf76678
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Apr 9 09:19:14 2009 -0700
added a submodule reference I will never make public. hahahahaha!Envoyez-lui un mail pour lui gueuler dessus.
VI-F-3. Superprojects▲
Parfois, les développeurs désirent séparer un gros projet en sous-répertoires en fonction de l'équipe qui travaille dessus. C'est logique que si vous venez de CVS ou de Subversion, où vous aviez l'habitude de définir un module ou un ensemble de sous-répertoires, que vous vouliez garder ce type de workflow.
Une bonne manière de le faire avec Git est de créer un dépôt Git pour chaque sous-dossiers, et de créer un super-projet contenant les différents modules. Le bénéfice de cette approche est de pouvoir spécifier les relations entre les projets avec des étiquettes et des branches depuis le super-projet.
VI-F-4. Les problèmes avec les sous-modules▲
Cependant, utiliser des sous-modules ne se déroule pas sans accroc. Premièrement, vous devez être relativement prudent lorsque vous travaillez dans le répertoire du sous-module. Lorsque vous exécutez git submodule update, cela récupère une version spécifique d'un projet, mais pas à l'intérieur d'une branche. Cela s'appelle avoir la tête en l'air (detached head), c'est-à-dire que votre HEAD référence directement un commit, pas une référence symbolique. Le problème est que vous ne voulez généralement pas travailler dans un environnement tête en l'air, car il est facile de perdre des modifications dans ces conditions. Si vous faites un premier git submodule update, consignez des modifications dans ce sous-module sans créer vous-même de branche pour y travailler, et que vous exécutez un nouveau git submodule update depuis le projet parent sans y avoir consigné pendant ce temps, Git écrasera vos modifications sans vous le dire. Techniquement, vous ne perdrez pas votre travail, mais vous n'aurez aucune branche s'y référant, il sera donc assez difficile de le récupérer.
Pour éviter ce problème, créez toujours une branche lorsque vous travaillez dans un répertoire de sous-module avec git checkout -b work ou une autre commande équivalente. Lorsque vous mettrez à jour le sous-module une deuxième fois, Git réinitialisera toujours votre travail, mais vous aurez au moins une référence pour y retourner.
Commuter de branches qui contiennent des sous-modules peut également s'avérer difficile. Si vous créez une nouvelle branche, y ajoutez un sous-module, et revenez ensuite à une branche sans ce sous-module, vous aurez toujours le répertoire de ce sous-module comme un répertoire non suivi :
$ git checkout -b rack
Switched to a new branch "rack"
$ git submodule add git@github.com:schacon/rack.git rack
Initialized empty Git repository in /opt/myproj/rack/.git/
...
Receiving objects: 100% (3184/3184), 677.42 KiB | 34 KiB/s, done.
Resolving deltas: 100% (1952/1952), done.
$ git commit -am 'added rack submodule'
[rack cc49a69] added rack submodule
2 files changed, 4 insertions(+), 0 deletions(-)
create mode 100644 .gitmodules
create mode 160000 rack
$ git checkout master
Switched to branch "master"
$ git status
# On branch master
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
#
# rack/Vous devez soit déplacer ce répertoire hors de votre dépôt local, soit le supprimer, dans ce dernier ca, vous devrait le clôner une nouvelle fois lorsque vous recommuterez et vous pouvez donc perdre des modifications ou des branches locales si vous ne les avez pas poussées.
Le dernier piège dans lequel beaucoup tombe est de passer des sous-répertoires à des sous-modules. Si vous suiviez des fichiers dans votre projet et que vous voulez les déplacer dans un sous-module, vous devez être très prudent, ou Git vous mangera. Présumons que vous avez des fichiers rack dans un sous-répertoire de votre projet, et que vous voulez les transformer en un sous-module. Si vous supprimez le sous-répertoire et que vous exécutez submodule add, Git vous hurle dessus avec :
$ rm -Rf rack/
$ git submodule add git@github.com:schacon/rack.git rack
'rack' already exists in the indexVous devez d'abord supprimer le répertoire rack de la zone d'attente. Vous pourrez ensuite ajouter le sous-module :
$ git rm -r rack
$ git submodule add git@github.com:schacon/rack.git rack
Initialized empty Git repository in /opt/testsub/rack/.git/
remote: Counting objects: 3184, done.
remote: Compressing objects: 100% (1465/1465), done.
remote: Total 3184 (delta 1952), reused 2770 (delta 1675)
Receiving objects: 100% (3184/3184), 677.42 KiB | 88 KiB/s, done.
Resolving deltas: 100% (1952/1952), done.Maintenant, supposons que vous avez fait cela dans une branche. Si vous essayer de commuter dans une ancienne branche où ces fichiers sont toujours dans l'arbre de projet plutôt que comme sous-module, vous aurez cette erreur :
$ git checkout master
error: Untracked working tree file 'rack/AUTHORS' would be overwritten by merge.Vous devez déplacer le répertoire du sous-module rack en dehors de votre dépôt local avant de pouvoir commuter vers une branche qui ne l'a pas :
$ mv rack /tmp/
$ git checkout master
Switched to branch "master"
$ ls
README rackPuis, lorsque vous recommutez, vous aurez un répertoire rack vide. Vous pouvez soit exécuter git submodule update pour clôner une nouvelle fois, ou vous pouvez remettre votre répertoire /tmp/rack dans votre répertoire vide.
VI-G. Fusion de sous-arborescence▲
Maintenant que vous avez vu les difficultés qu'il peut y avoir avec le système de sous-module, voyons une alternative pour résoudre la même problématique. Lorsque Git fusionne, il regarde ce qu'il doit fusionner et choisit alors une stratégie de fusion appropriée. Si vous fusionnez deux branches, Git utilise une stratégie récursive (_recursive_ strategy). Si vous fusionnez plus de deux branches, Git choisit la stratégie de la pieuvre (_octopus_ strategy). Ces stratégies sont choisies automatiquement car la stratégie récursive peut gérer des problèmes comples de fusions à trois entrées, par exemple, plus d'un ancêtre commun, mais il ne peut gérer que deux branches. La fusion de la pieuvre peut gérer plusieurs branches mais il est plus prudent afin d'éviter les conflits difficiles, il est donc choisi comme stratégie par défaut si vous essayez de fusionner plus de deux branches.
Cependant, il existe d'autres stratégies que vous pouvez tout aussi bien choisir. L'une d'elles est la fusion de sous-arborescence, et vous pouvez l'utiliser pour gérer la problématique de sous-projet. Nous allons donc voir comme gérer l'inclusion de rack comme dans la section précédente, mais en utilisant cette fois-ci les fusion de sous-arborescence.
La fusion de sous-arborescence suppose que vous avez deux projets et que l'un s'identifie à un sous-répertoire de l'autre. Lorsque vous spécifiez une fusion de sous-arborescence, Git est assez intellignet pour deviner lequel est un sous-répertoire de l'autre et fusionne en conséquence, When you specify a subtree merge, Git is smart enough to figure out that one is a subtree of the other and merge appropriately - c'est assez bluffant.
Premièrement, vous ajoutez l'application Rack à votre projet. Vous ajoutez le projet Rack comme une référence distante dans votre propre projet et récupérez dans un branche personnelle :
$ git remote add rack_remote git@github.com:schacon/rack.git
$ git fetch rack_remote
warning: no common commits
remote: Counting objects: 3184, done.
remote: Compressing objects: 100% (1465/1465), done.
remote: Total 3184 (delta 1952), reused 2770 (delta 1675)
Receiving objects: 100% (3184/3184), 677.42 KiB | 4 KiB/s, done.
Resolving deltas: 100% (1952/1952), done.
From git@github.com:schacon/rack
* [new branch] build -> rack_remote/build
* [new branch] master -> rack_remote/master
* [new branch] rack-0.4 -> rack_remote/rack-0.4
* [new branch] rack-0.9 -> rack_remote/rack-0.9
$ git checkout -b rack_branch rack_remote/master
Branch rack_branch set up to track remote branch refs/remotes/rack_remote/master.
Switched to a new branch "rack_branch"Vous avez maintenant la racine du projet Rack dans votre branche rack_branch et votre propre projet dans la branche master. Si vous récupérez l'une puis l'autre branche, vous pouvez voir que vous avez différentes racines de projet :
$ ls
AUTHORS KNOWN-ISSUES Rakefile contrib lib
COPYING README bin example test
$ git checkout master
Switched to branch "master"
$ ls
READMEPour tirer le projet Rack dans votre projet master comme un sous répertoire, vous pouvez utiliser la commande git read-tree. Vous apprendrez d'avantage sur read-tree et compagnie dans le Chapitre 9, mais pour le moment, sachez qu'il lit la racine d'une de vos branche et l'inscrit dans votre zone d'attente et votre répertoire de travail. Vous venez juste de commuter vers votre branche master, et vous tirez la branche rack vers le sous-répertoire rack de votre branche master de votre projet principal :
$ git read-tree --prefix=rack/ -u rack_branchAu moment de consigner, vous verrez tout les fichiers de Rack de ce sous-répertoire, comme si vous les aviez copié depuis une archive. Ce qui est intéressant, c'est que vous pouvez assez facilement fusionner les changements d'une branche à l'autre. Par conséquence, s'il y a des mises à jour pour le projet Rack, vous pouvez les tirez depuis le dépôt principal en commutant dans cette branche et tirant les modifications :
$ git checkout rack_branch
$ git pullPuis, vous pouvez fusionner ces changements dans votre branche principale. Vous pouvez utiliser git merge -s subtree et cela fonctionnera, mais Git fusionnera également les historiques ensemble, ce que vous ne voulez probablement pas. Pour tirer les changements et préremplir le message de consignation, utilisez les options --squash et --no-commit avec l'option de stratégie -s subtree :
$ git checkout master
$ git merge --squash -s subtree --no-commit rack_branch
Squash commit -- not updating HEAD
Automatic merge went well; stopped before committing as requestedToutes les modifications de votre projet Rack sont fusionné et prêtes à être consignées localement. Vous pouvez également faire le contraire, faire des modifications dans le sous-répertoire rack de votre branche principale et les fusionner plus tard dans votre branche rack_branch pour les envoyer aux mainteneurs du projet Rack ou les pousser dans le dépôt principal.
Pour voir les différences entre ce que vous avez dans le sous-répertoire rack et le code de la branche rack_branch (pour savoir si vous devez les fusionner), vous ne pouvez pas utiliser la commande diff habituelle. Vous devez plutôt exécutez git diff-tree en renseignant la branche avec laquelle vous voulez comparer :
$ git diff-tree -p rack_branchOu, pour comparer ce qu'il y a dans votre répertoire rack avec ce qu'il y avait sur le server la dernière fois que vous avez vérifié, vous pouvez exécuter :
$ git diff-tree -p rack_remote/masterVI-H. Résumé▲
Vous venez de voir certains des outils avancés vous permettant de manipuler vos consignations et votre zone d'attente plus précisemment. Lorsque vous remarquez des bogues, vous devriez être capable de facilement trouver quelle consignation les a introduits, quand et par qui. Si vous voulez utiliser des sous-projets dans votre projet, vous avez appris plusieurs façons de les gérer. À partir de maintenant, vous devez être capable de faire la majorité de ce que vous avez besoin avec Git en ligne de commande et de vous y sentir à l'aise.
